
GRPO#
Note
Reinforcement learning (RL) has been proven to be effective in further improving the overall ability of LLMs after the Supervised Fine-Tuning (SFT) stage. DeepSeek Math introduces an RL algorithm, Group Relative Policy Optimization (GRPO), which has proven to be both efficient and effective.
PPO Review#
Proximal Policy Optimization (PPO) is an actor-critic RL algorithm that is widely used in the RL fine-tuning stage of LLMs. In particular, it optimizes LLMs by maximizing the following objective:
where \(\pi_{\theta}\) and \(\pi_{\theta_{\text{old}}}\) are the current and old policy models, and \(q\), \(o\) are questions and outputs sampled from the question dataset and the old policy \(\pi_{\theta_{\text{old}}}\) respectively. \(\epsilon\) s a clipping-related hyper-parameter introduced in PPO for stabilizing training. \(A_{t}\) is the advantage, which is computed by applying Generalized Advantage Estimation (GAE), based on the rewards \(\{r_{\ge t}\}\) and a learned value function \(V_{\psi}\) (this blog for detail):
Compute per-token rewards:
\(\text{KL}(t) = \log({\pi_{\theta_{\text{old}}}(o_{t}|q,o<t)}/{\pi_{\text{ref}}(o_{t}|q,o<t)})\)
If \(t\) is not the last token \(r_{t} = -\beta\text{KL}(t)\)
If \(t\) is the last token \(r_{t} = r_{\phi}(q, o) - \beta\text{KL}(t)\)
\(\sum_{t=1}^{T}r_{t} = r_{\phi}(q, o) - \beta\log({\pi_{\theta_{\text{old}}}(o|q)}/{\pi_{\text{ref}}(o|q)})\) is the reward PPO aims to optimize.
Compute TD error \(\delta_{t} = r_{t} + \gamma V_{\psi}(t+1) - V_{\psi}(t) \).
Compute Advantage Function using GAE: \(A_{t} = \sum(\gamma\lambda)^{l}\delta_{t+l}\).
GRPO#
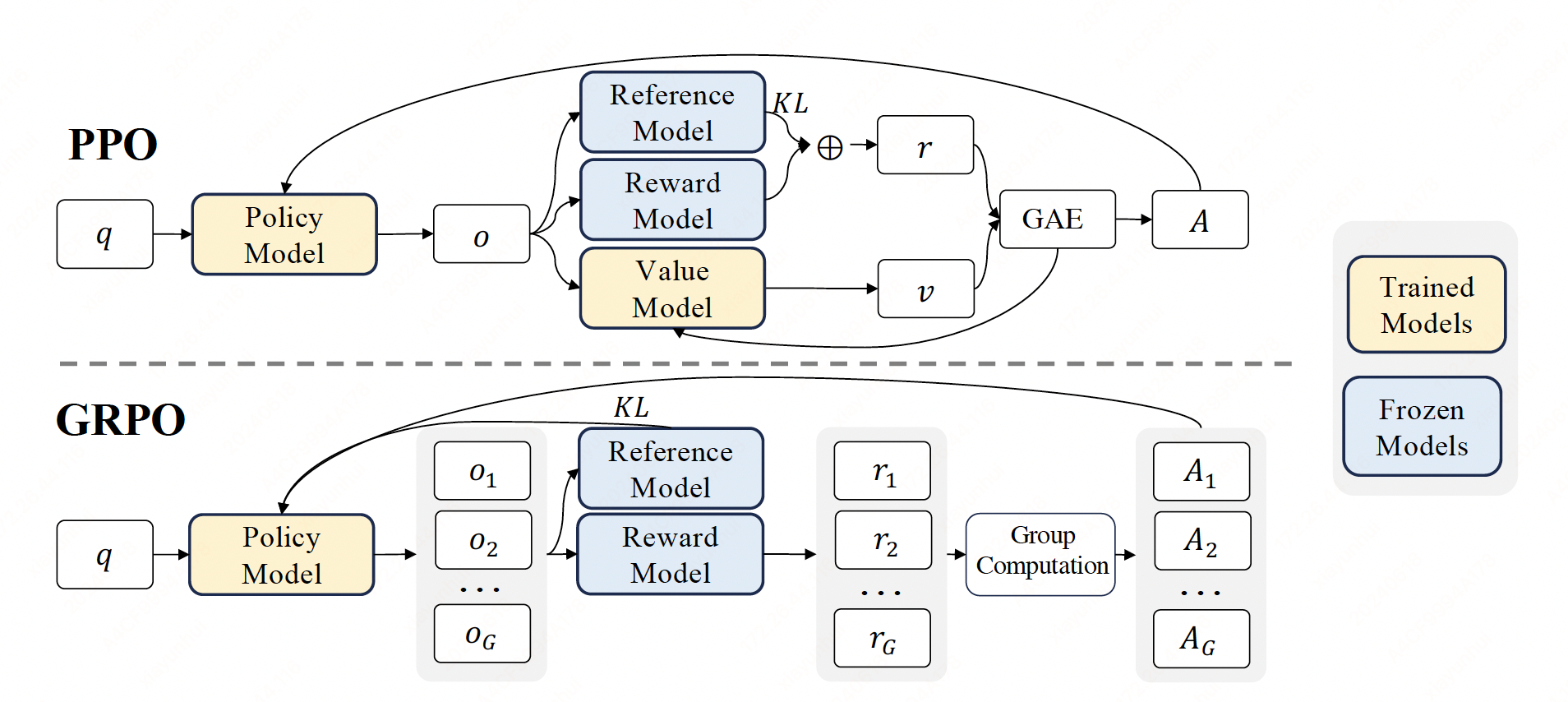
To address this, we propose Group Relative Policy Optimization (GRPO), for each question \(q\), GRPO samples a group of outputs \(\{o_1, o_2, \dots , o_G\}\) from the old policy \(\pi_{\theta_{old}}\) and then optimizes the policy model by maximizing the following objective:
where \(\epsilon\) and \(\beta\) are hyper-parameters, and \(\hat{A}_{i,t}\) is the advantage calculated based on relative rewards of the outputs inside each group only. Also note that, instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss, avoiding complicating the calculation of \(\hat{A}_{i,t}\). And different from the KL penalty term used in PPO, we estimate the KL divergence with the following unbiased estimator:
which is guaranteed to be positive.
Tip
A good estimator is unbiased (it has the right mean) and has low variance.
Since:
So \(\mathbb{E}_{x\sim P}\left[\frac{Q(x)}{P(x)} - \log\frac{Q(x)}{P(x)} - 1\right]\) is an unbiased estimator of the KL divergence.
Outcome Supervision RL with GRPO#
Formally, for each question \(q\), a group of outputs \(\{o_1,o_{2},\dots,o_{G}\}\) are sampled from the old policy model \(\pi_{\theta_{\text{old}}}\). A reward model is then used to score the outputs, yielding \(G\) rewards \(\mathbf{r}=\{r_1,r_{2},\dots,r_{G}\}\) correspondingly.
Subsequently, these rewards are normalized by subtracting the group average and dividing by the group standard deviation. Outcome supervision provides the normalized reward at the end of each output \(o_{i}\) and sets the advantages \(\hat{A}_{i,t}\) of all tokens in the output as the normalized reward:
Tip
GRPO 的优势:
没有 critic model,省资源。
组内标准分(z-score)方式天然去除了奖励尺度和偏移的影响,降低了梯度更新的方差。
GRPO Configuration in verl#
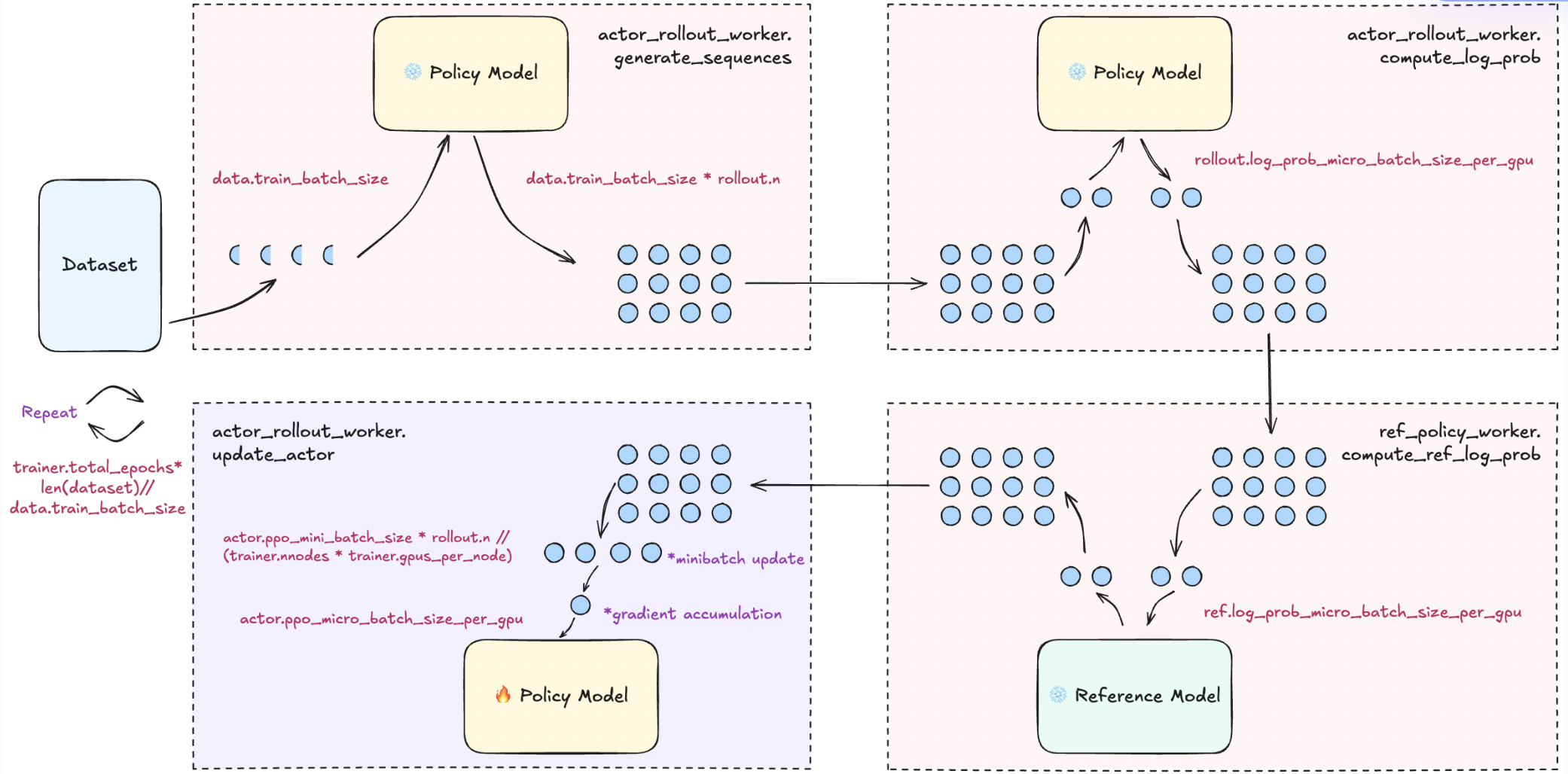
actor_rollout.ref.rollout.n: For each prompt, sample \(n\) times. For GRPO, please set it to a value larger than 1 for group samplingdata.train_batch_size: The global batch size of prompts used to generate a set of sampled trajectories/rollouts. The number of responses/trajectories isdata.train_batch_size * actor_rollout.ref.rollout.n.actor_rollout_ref.actor.ppo_mini_batch_size: The set of sampled trajectories is split into multiple mini-batches with batch_size=ppo_mini_batch_size for PPO actor updates. The ppo_mini_batch_size is a global size across all workers.actor_rollout_ref.actor.ppo_epochs: Number of epochs for GRPO updates on one set of sampled trajectories for actoractor_rollout_ref.actor.clip_ratio: The GRPO clip range. Default to 0.2algorithm.adv_estimator: Default is gae. Please set it to grpo insteadactor_rollout_ref.actor.loss_agg_mode: Default is “token-mean”. Options include “token-mean”, “seq-mean-token-sum”, “seq-mean-token-mean”. The original GRPO paper takes the sample-level loss (seq-mean-token-mean), which may be unstable in long-CoT scenarios.
Instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss:
actor_rollout_ref.actor.use_kl_loss: To use kl loss in the actor. When used, we are not applying KL in the reward function. Default is False. Please set it to True for GRPO.actor_rollout_ref.actor.kl_loss_coef: The coefficient of kl loss. Default is 0.001.actor_rollout_ref.actor.kl_loss_type: Support kl(k1), abs, mse(k2), low_var_kl(k3) and full. How to calculate the kl divergence between actor and reference policy.