s1: Simple test-time scaling#
Note
Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. We seek the simplest approach to achieve test-time scaling and strong reasoning performance.
We curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations:
difficulty,diversity, andquality.We develop budget forcing to control test-time compute by forcefully terminating the model’s thinking process or lengthening it by appending “Wait” multiple times to the model’s generation when it tries to end.
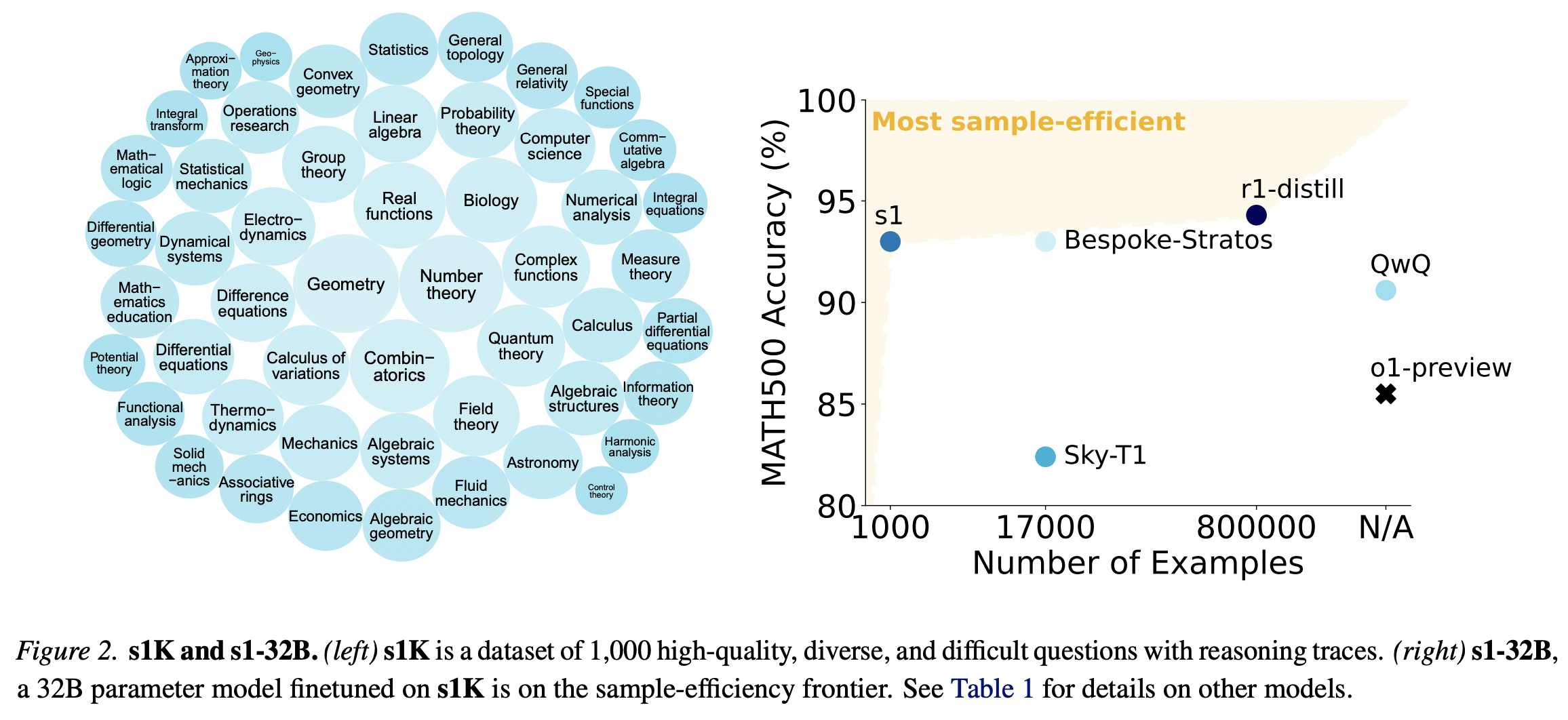
After supervised finetuning the Qwen2.5- 32B-Instruct language model on s1K and equipping it with budget forcing, our model s1-32B exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24).
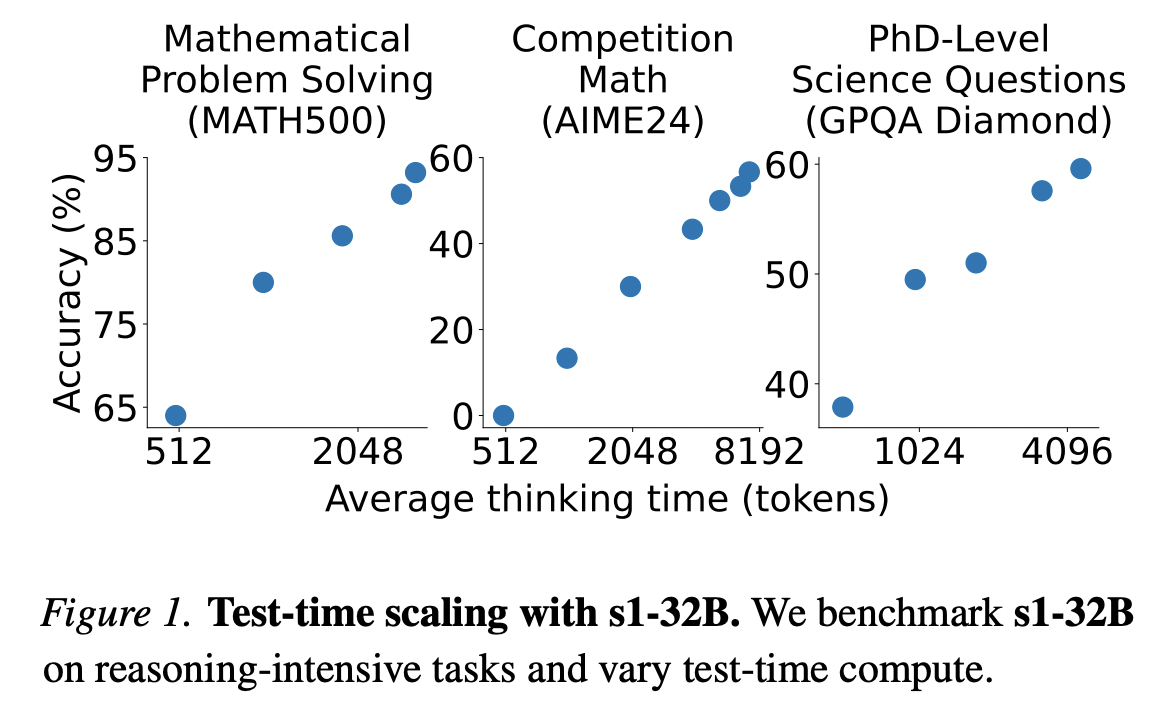
Reasoning data curation to create s1K#
We could directly train on our pool of 59K questions, however, our goal is to find the simplest approach with minimal resources.
Quality E.g. filter out low-quality examples by checking if they contain non-existent image references.
Difficulty For difficulty, we use two indicators: model performance
and reasoning trace length. We evaluate two models
on each question: Qwen2.5-7B-Instruct and Qwen2.5-
32B-Instruct, with correctness assessed by Claude 3.5 Sonnet comparing each attempt against the reference solution.

Diversity To quantify diversity, we classify questions into domains using Claude 3.5 Sonnet based on the Mathematics Subject Classification (MSC) system. We first choose one domain uniformly at random. Then, we sample one problem from this domain according to a distribution that favors longer reasoning traces as motivated in Difficulty. We repeat this process we have 1,000 total samples spanning 50 domains.
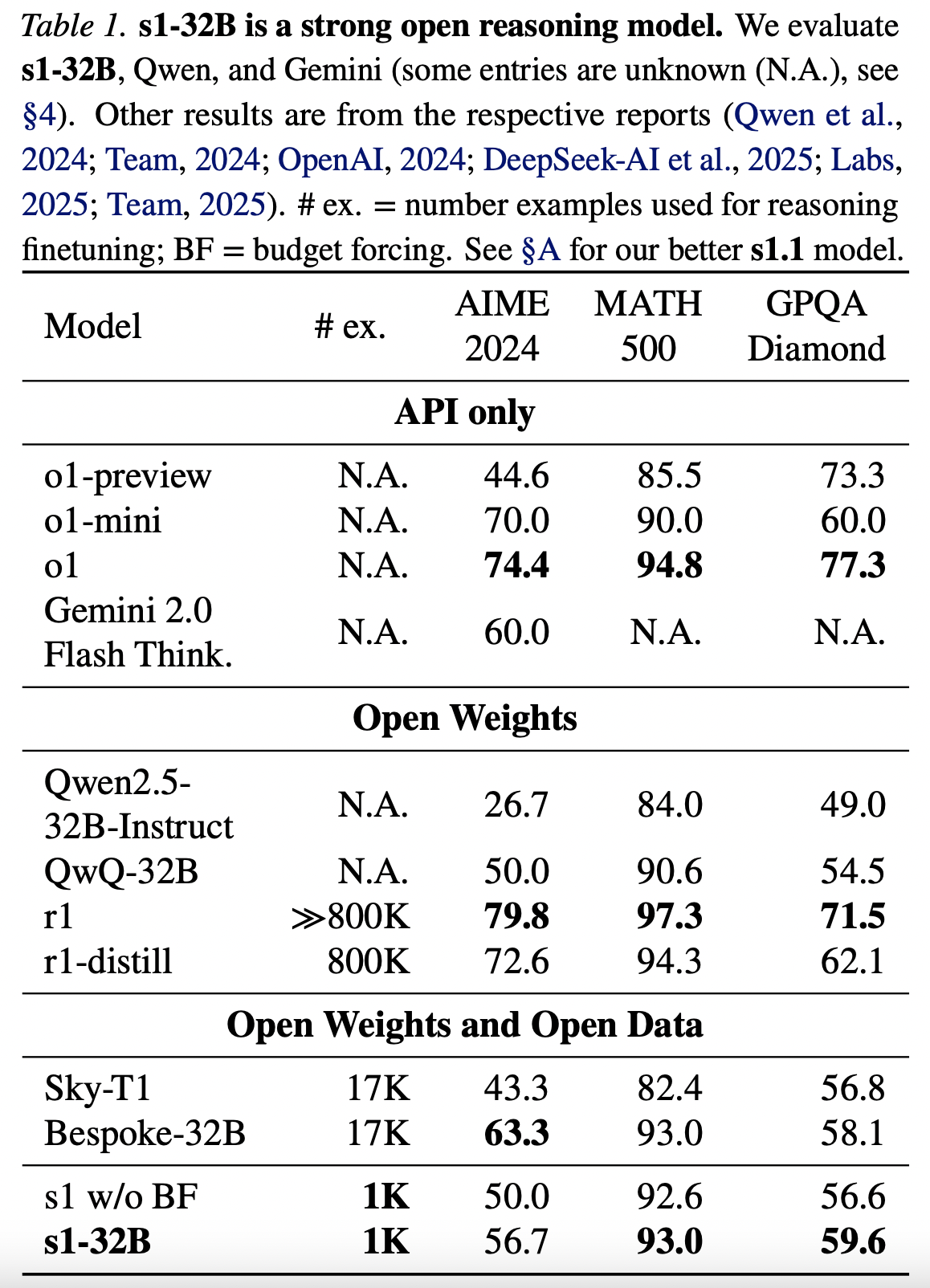
Test-time scaling#
We classify test-time scaling methods into:
Sequential, where later computations depend on earlier ones (e.g., a long reasoning trace)
Parallel, where computations run independently (e.g., majority voting)
Budget forcing We propose a simple decoding-time intervention by forcing a maximum and/or minimum number of thinking tokens. Specifically, we enforce a maximum token count by simply appending the end-of-thinking token delimiter and optionally “Final Answer:” to early exit the thinking stage and make the model provide its current best answer. To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation.

Metrics We establish a set of evaluation metrics to measure test-time scaling across methods. Importantly, we do not only care about the accuracy a method can achieve but also its controllability and test-time scaling slope. We measure three metrics:
where \(a_{\text{min}}\), \(a_{\text{max}}\) refer to a pre-specified minimum and maximum amount of test-time compute; in our case thinking tokens. We usually only constrain \(a_{\text{max}}\).
Scaling is the average slope of the piece-wise linear function. It must be positive for useful methods and larger is better.
Performance is simply the maximum performance the method achieves on the benchmark.
Results#
Training We perform supervised finetuning on Qwen2.5- 32B-Instruct using s1K to obtain our model s1-32B. Finetuning took 26 minutes on 16 NVIDIA H100 GPUs with PyTorch FSDP.
Evaluation