
Qwen2.5-Coder#
Note
Qwen2.5-Coder[HYC+24] is built upon the Qwen2.5[QY+25] architecture and continues pretrained on a vast corpus of over 5.5 trillion tokens. Through meticulous data cleaning, scalable synthetic data generation, and balanced data mixing, Qwen2.5-Coder demonstrates impressive code generation capabilities while retaining general and math skills.
Pre-training#
Data Composition#
Source Code We collected public repositories from GitHub created before February 2024, spanning 92 programming languages.
Text-Code Grounding Data We curated a large-scale and high-quality text-code mixed dataset from Common Crawl, which includes code-related documentation, tutorials, blogs, and more.
Synthetic Data Synthetic data offers a promising way to address the anticipated scarcity
of training data. We used CodeQwen1.5, the predecessor of Qwen2.5-Coder, to generate
large-scale synthetic datasets. To mitigate the risk of hallucinations during this process, we
introduced an executor for validation, ensuring that only executable code was retained.
Math Data To enhance the mathematical capabilities of Qwen2.5-Coder, we integrated the pre-training corpus from Qwen2.5-Math[YZH+24] into the Qwen2.5-Coder dataset. Importantly, the inclusion of mathematical data did not negatively impact the model’s performance on code tasks.
Text Data Similar to the Math Data, we included high-quality general natural language data from the pre-training corpus of the Qwen2.5 model to preserve Qwen2.5-Coder’s general capabilities.
Data Mixture#
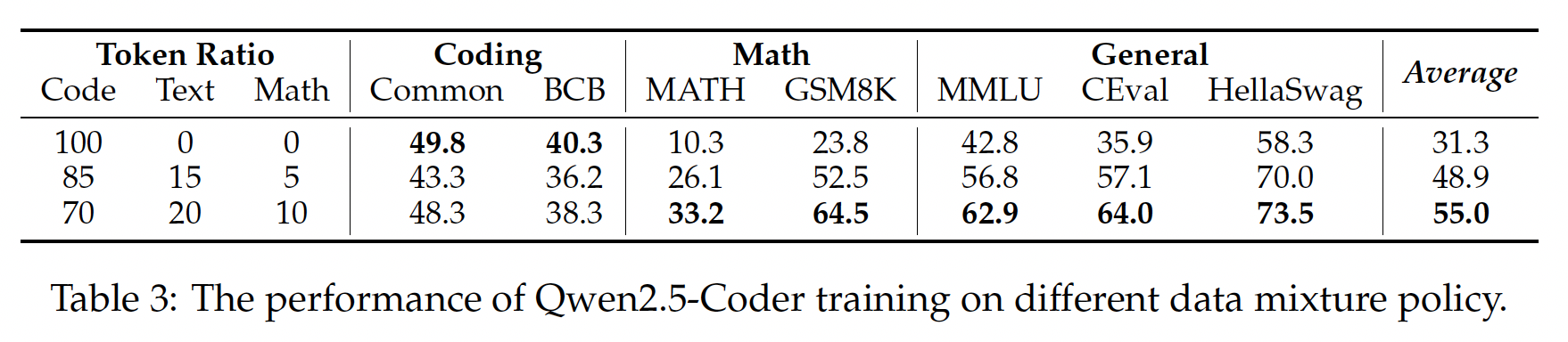
Balancing Code, Math, and Text data is crucial for building a foundational model. Interestingly, we found that the 7:2:1 ratio outperformed the others, even surpassing the performance of groups with a higher proportion of code.
Training Policy#

We employed a three-stage training approach to train Qwen2.5-Coder, including file-level pretraining, repo-level pretraining, and instruction tuning.
Post-training#
A Recipe for Instruction Data#
Multilingual Programming Code Identification We fine-tune a CodeBERT to perform the language identification model to categorize documents into nearly 100 programming languages.
Instruction Synthesis from GitHub For the unsupervised data (code snippets) massively existing in many websites (e.g. GitHub), we try to construct the supervised instruction dataset using LLM. Specifically, we use the LLM to generate the instruction from the code snippets within 1024 tokens and then we use the code LLM to generate the response (Magicoder, Unicoder, Wavecoder). Finally, we use the LLM scorer to filter the low-quality ones to obtain the final pair. Given the code snippets of different programming languages, we construct an instruction dataset from the code snippets. To fully unleash the potential of our proposed method, we also include the open-source instruction dataset (e.g. McEval-Instruct[CLY+24] for massively multilingual code generation and debugging) in the seed instruction dataset. Finally, we combine the instruction data from the GitHub code snippet and open-source instructions for supervised fine-tuning.
Multilingual Code Instruction Data To bridge the gap among different programming languages, we propose a multilingual multi-agent collaborative framework to synthesize the multilingual instruction corpora.
Checklist-based Scoring for Instruction Data To completely evaluate the quality of the created instruction pair, we introduce several scoring points for each sample:
Question&Answer Consistency: Whether Q&A are consistent and correct for fine-tuning.
Question&Answer Relevance: Whether Q&A are related to the computer field.
Question&Answer Difficulty: Whether Q&A are sufficiently challenging.
Code Exist: Whether the code is provided in question or answer.
Code Correctness: Evaluate whether the provided code is free from syntax errors and logical flaws.
Consider factors like proper variable naming, code indentation, and adherence to best practices.
Code Clarity: Assess how clear and understandable the code is.
Code Comments: Evaluate the presence of comments and their usefulness in explaining the code’s functionality.
Easy to Learn: determine its educational value for a student whose goal is to learn basic coding concepts.
After gaining all scores \((s_1, \dots, s_n)\), we can get the final score with \(s = w_1 s_1 + \dots + w_n s_n\), where \((w_1, \dots ,w_n)\) are a series of pre-defined weights.
A multilingual sandbox for code verification Only the self-contained (e.g. algorithm problems) code snippet will be fed into the multilingual sandbox.
Decontamination#
To ensure that Qwen2.5-Coder does not produce inflated results due to test set leakage, we performed decontamination on all data, including both pre-training and post-training datasets. We removed key datasets such as HumanEval, MBPP, GSM8K, and MATH. The filtering was done using a 10-gram overlap method, where any training data with a 10-gram word-level overlap with the test data was removed.
Training Policy#
Coarse-to-fine Fine-tuning We first synthesized tens of millions of low-quality but diverse instruction samples to fine-tune the base model. In the second stage, we adopt millions of high-quality instruction samples to improve the performance of the instruction model with rejection sampling and supervised fine-tuning. For the same query, we use the LLM to generate multiple candidates and then use the LLM to score the best one for supervised fine-tuning.
Mixed Tuning We optimize the instruction model with a majority of standard SFT data and a small part of FIM instruction samples.
Direct Preference Optimization for Code After obtaining the SFT model, we further align the Qwen2.5-Coder with the help of offline direct preference optimization (DPO). Given that human feedback is highly labor-intensive, we use a multilingual code sandbox to provide code execution feedback, while an LLM is utilized for human judgment feedback. For the algorithm-like and self-contained code snippets, we generate the test cases to check the correctness of the code as the code execution feedback, including Python, Java, and other languages. For other complex code snippets, we use LLM-as-ajudge to decide which code snippet is better. Further, we combine the code DPO data and common data for offline DPO training.