
OpenCodeReasoning#
Note
Since the advent of reasoning-based large language models, many have found great success from distilling reasoning capabilities into student models. However, much of the progress on distilling reasoning models remains locked. To address this, we construct a superior supervised fine-tuning (SFT) dataset that we use to achieve state-of-the-art coding capability results in models of various sizes.
Dataset Construction and Refinement#
Coding Questions Collection#
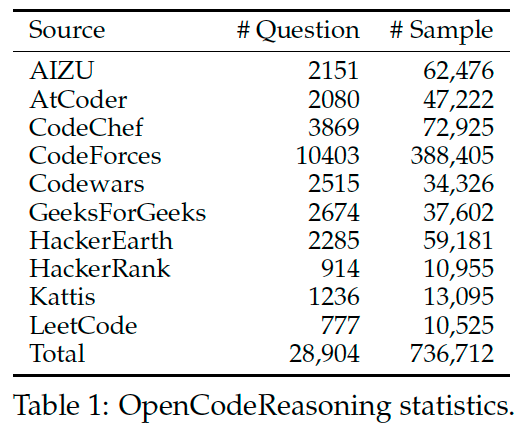
To construct OPENCODEREASONING, we gathered questions from TACO, APPS, CodeContests, and CodeForces from the OpenR1 project. We performed exact-match deduplication, resulting in 28,904 distinct questions across a range of difficulties.
Solution Code Generation#
In this step, we generate multiple solutions per question using the DeepSeek-R1. We primarily generate solutions in Python programming language. All solutions are sampled via Nucleus
Sampling, using temperature 0.6, top-p 0.95, and explicitly injecting
<think> tag to force the model to generate reasoning traces. We use SGLang for R1 generations with a maximum output sequence length of 16k tokens.
Post-Processing for Refinement#
Verify whether the solution includes reasoning traces enclosed within
<think>and</think>tags.Verify the presence of a code block within the solution segments.
Filter out responses where the generated reasoning traces contain code blocks.
Verify the syntactic correctness of the solution code blocks by parsing them using
Tree Sitter.
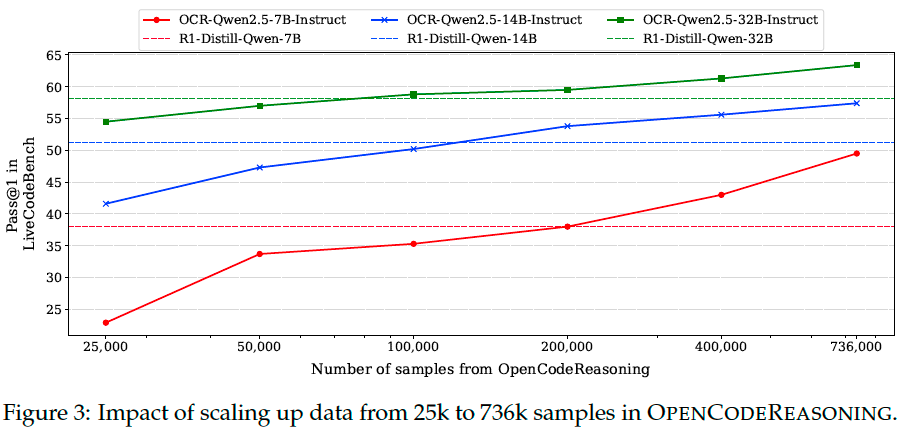
Scaling Up Data in Stages#
We find that while reasoning ability itself may be induced with a minute amount of data, to achieve state-of-the-art results on coding benchmarks, large datasets are necessary. The most significant gains in benchmark scores were observed by simply increasing the number of unique, varied, and difficult questions.
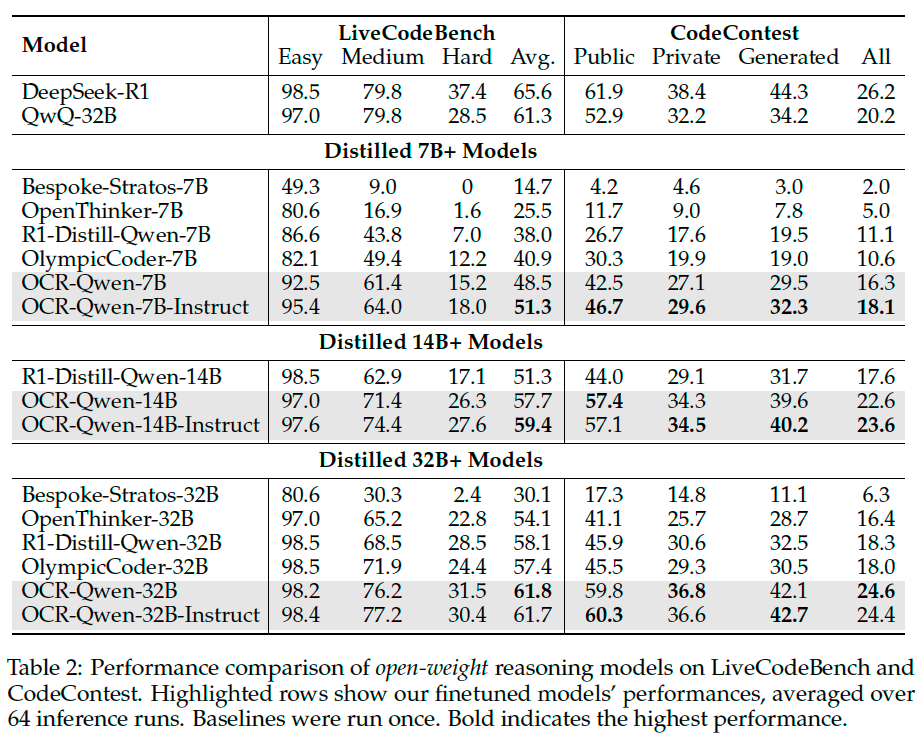
Main Evaluation#
Ablation and Analyses#
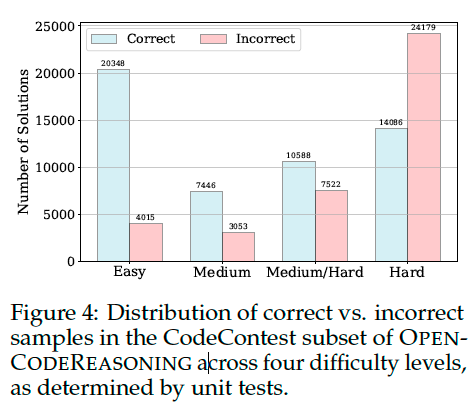
Ablation: Filtering by Code Execution#
We fine-tuned Qwen-2.5-14B-Instruct using three subsamples:
the full subsample of 445k instances;
selecting all instances that pass unit-tests (151k instances);
selecting an equal number of samples as in (2) that fail all tests.
Surprisingly, we observed that fine-tuning on incorrect solutions results in higher accuracy than on correct solutions.

Investigating further, we identified that incorrect solutions span questions that are more challenging than the ones associated with the correct solutions.
Ablation: Inclusion of C++ Solutions#
The inclusion of C++ solutions has no positive impact on Python benchmark performance, but does significantly improve the accuracy on the C++ benchmark.