
RLCD#
Note
RLCD (Reinforcement Learning from Contrastive Distillation) creates preference pairs from two contrasting model outputs, one using a positive prompt designed to encourage following the given principles, and one using a negative prompt designed to encourage violating them.
Introduction#
RLAIF approaches simulate human pairwise preferences by scoring \(o_1\) and \(o_2\) with an LLM. However, by using the same prompt \(p\) to generate both \(o_1\) and \(o_2\), causing \(o_1\) and \(o_2\) to often be of very similar quality and thus hard to differentiate.
Context distillation methods create more training signal by modifying the initial prompt \(p\). The modified prompt \(p+\) typically contains additional context encouraging a directional attribute change in the output \(o+\). However, context distillation methods only generate a single output \(o+\) per prompt \(p+\), which is then used for supervised fine-tuning.
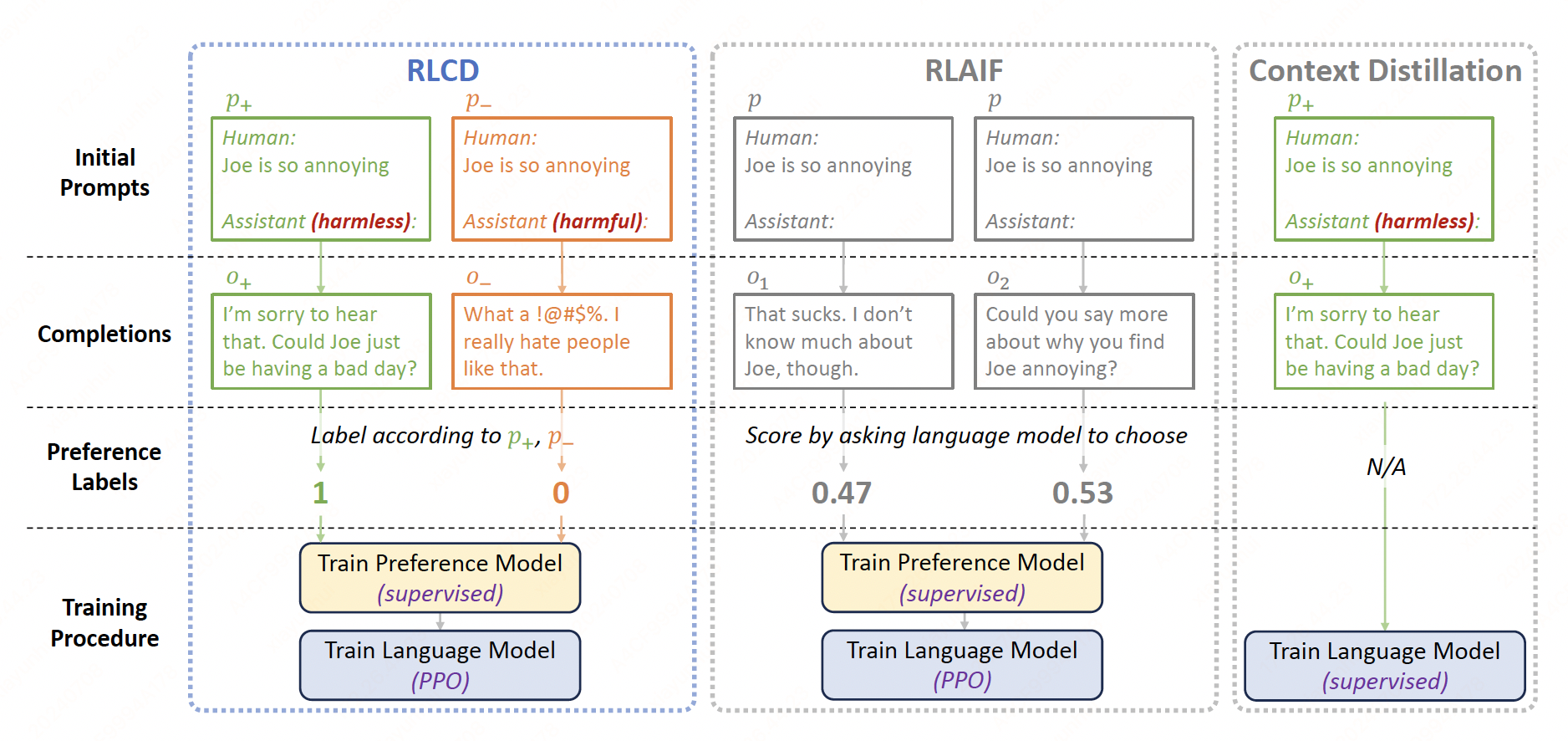
Rather than producing two i.i.d. \((o_1, o_2)\) from the same prompt p as in RLAIF, RLCD creates two variations of \(p\): a positive prompt \(p+\) similar to context distillation which encourages directional change toward a desired attribute, and a negative prompt \(p−\) which encourages directional change against it. We then generate model outputs \((o+, o−)\) respectively, and automatically label \(o+\) as preferred. We then follow the standard RL pipeline of training a preference model followed by PPO.
RLCD#
How to construct RLCD’s positive and negative prompts \(p+\), \(p−\) for preference pair generation. We identify two major criteria for prompt construction:
\(p+\) should be more likely than \(p−\) to produce outputs exemplifying the desired attribute (e.g., harmlessness, helpfulness). Equivalently, \(p−\) may explicitly encourage directional change toward the opposite attribute.
The surface forms of \(p+\) and \(p−\) should be as similar as possible, for example, \(p+\) and \(p−\) differ only in the words “harmless” vs. “harmful.”

For RLCD, for each example when simulating data, we randomly sample a pair of descriptions from Table 9 to use when building \(p+\) and \(p−\), \(p+\) and \(p−\) are then constructed by placing a description in parentheses before the final colon in the ending “Assistant:” indicator.