GPT2#
Note
Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on taskspecific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText.

Training Dataset#
Most prior work trained language models on a single domain of text, such as news articles, Wikipedia, or fiction books. Our approach motivates building as large and diverse a dataset as possible in order to collect natural language demonstrations of tasks in as varied of domains and contexts as possible.
A promising source of diverse and nearly unlimited text is web scrapes such as Common Crawl. While these archives are many orders of magnitude larger than current language modeling datasets, they have significant data quality issues.
Instead, we created a new web scrape which emphasizes document quality. We scraped all outbound links from Reddit, a social media platform, which received at least 3 karma. The resulting dataset, WebText, contains the text subset of these 45 million links.
Tip
We use Byte Pair Encoding (BPE), this input representation allows us to combine the empirical
benefits of word-level LMs with the generality of byte-level
approaches.
Model#
We use a Transformer based architecture for our LMs. The model largely follows the details of the OpenAI GPT model with a few modifications. Layer normalization was moved to the input of each sub-block, depicted in Normalization, and an additional layer normalization was added after the final self-attention block.
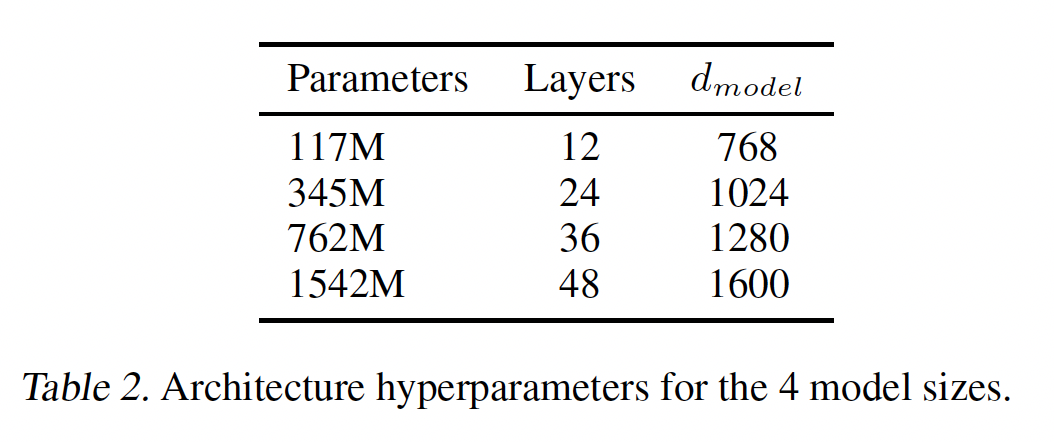
We trained and benchmarked four LMs with approximately log-uniformly spaced sizes. The architectures are summarized in Table 2. The smallest model is equivalent to the original GPT, and the second smallest equivalent to the largest model from BERT[DCLT19]. Our largest model, which we call GPT-2, has over an order of magnitude more parameters than GPT.