
LIMA: Less Is More for Alignment#
Note
Large language models are trained in two stages:
pretraining
instruction tuning and reinforcement learning
We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses. LIMA demonstrates remarkably strong performance, strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
Alignment Data#
We curate 1,000 examples that approximate real user prompts and high-quality responses. We select 750 top questions and answers from community forums, such as Stack Exchange and wikiHow, sampling for quality and diversity. In addition, we manually write 250 examples of prompts and responses.
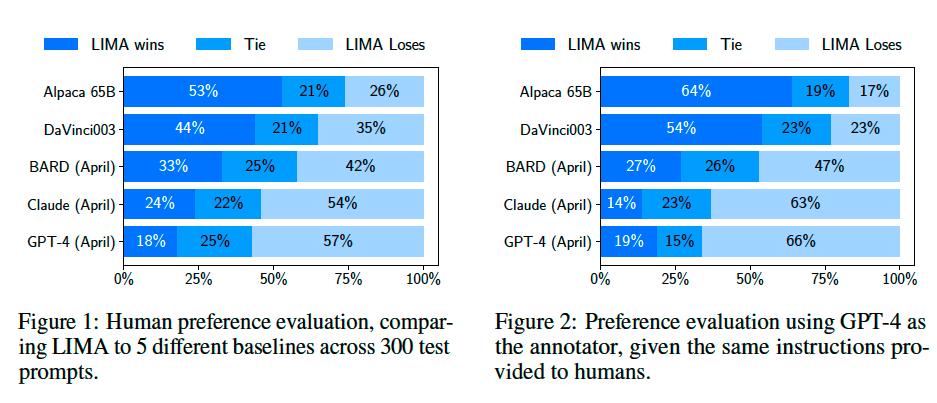
Human Evaluation#
Ablations on Data Diversity, Quality, and Quantity#
We investigate the effects of training data diversity, quality, and quantity through ablation experiments.
We observe that, for the purpose of alignment, scaling up input diversity and output quality have
measurable positive effects, while scaling up quantity alone might not.
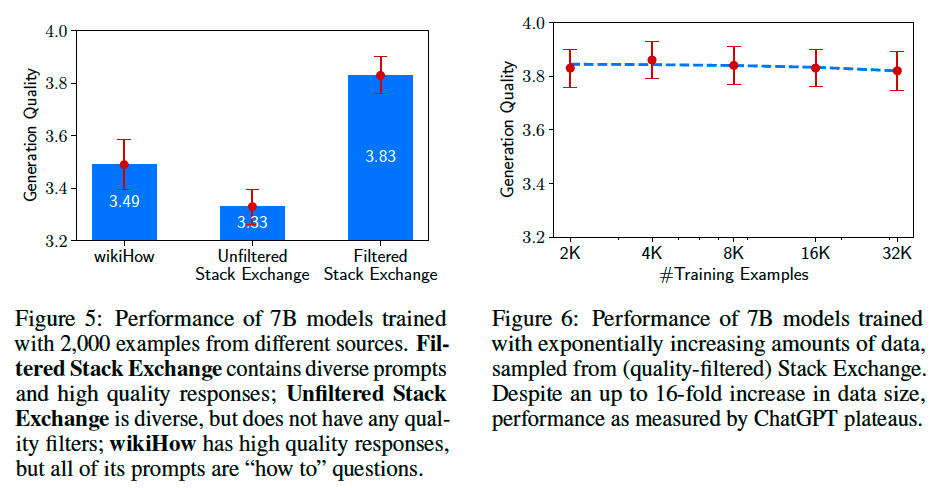
Caution
Confilict with the statement that “the model performance has a log-linear relation versus data amount”.