
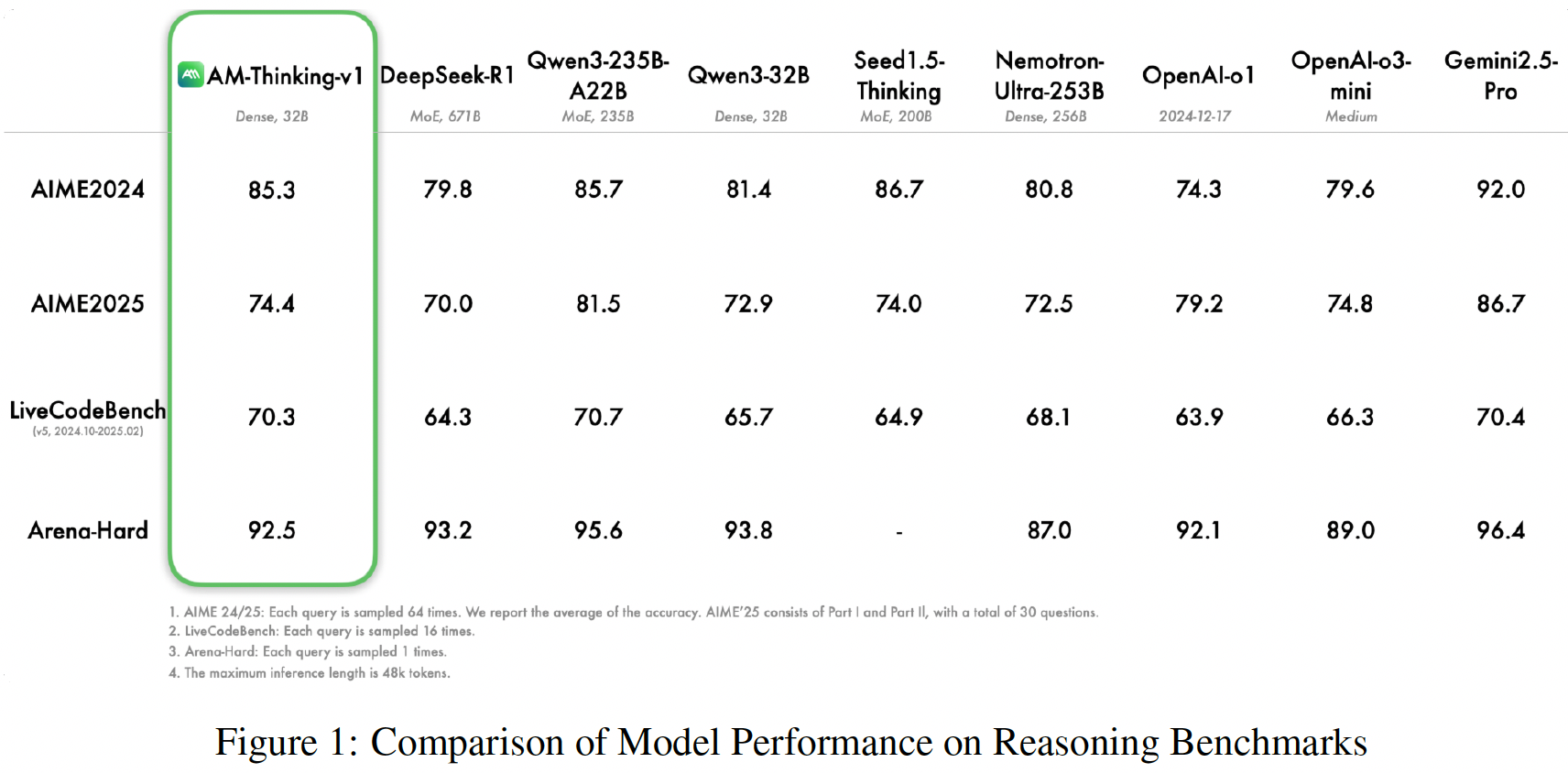
AM-Thinking-v1#
Note
Built entirely from the open-source Qwen2.5-32B base model and publicly available queries, AM-Thinking-v1 leverages a meticulously crafted post-training pipeline — combining supervised fine-tuning and reinforcement learning — to deliver exceptional reasoning capabilities.
Data#
Data Collection#
Our training data is collected from multiple publicly available open source datasets, spanning tasks such as mathematical reasoning, code generation, scientific reasoning, instruction follow, and general chat.
Code Generation. We ensure that all collected code data include verifiable test cases. Datasets selected for this category include PRIME, DeepCoder, KodCode, Livecodebench (before 24.10), codeforces_cots, verifiable_coding, opencoder, OpenThoughts-114k-Code_decontaminated, and AceCode-87K.
Query filtering#
Removal of queries containing URLs.
Removal of image-referencing queries.
Tip
Mathematical data may have incorrect ground truths. For each query, we prompt DeepSeek-R1 to generate multiple responses
and compare the most frequent answer (Deepseek-R1-common) with the original ground truth using
math_verify. Discrepancies between model predictions and the original ground truth prompt us
to re-evaluate the correctness of certain annotations. For these cases, we consult o4-mini to
obtain an alternative answer (o4-mini-answer). If math_verify determines that o4-mini-answer and
Deepseek-R1-common produce equivalent results, we consider the original ground truth potentially
incorrect and revise it to o4-mini-answer.
Synthetic response filtering#
Perplexity-based Filtering. Responses with PPL scores exceeding a predefined threshold are discarded.
N-gram-based Filtering. We discard model responses containing
repeated phrasesof a certain minimum length that appear consecutively.Structure-based Filtering. We require that each model-generated reply contains both a complete think and answer component.
Reward#
Code. For code queries equipped with predefined test cases, the verification process is executed within a secure code sandbox environment.
Non-Verifiable Queries. For queries lacking objective verification criteria, reward score is conducted using a reward modelbased approach.
Approach#
Supervised Fine-Tuning#
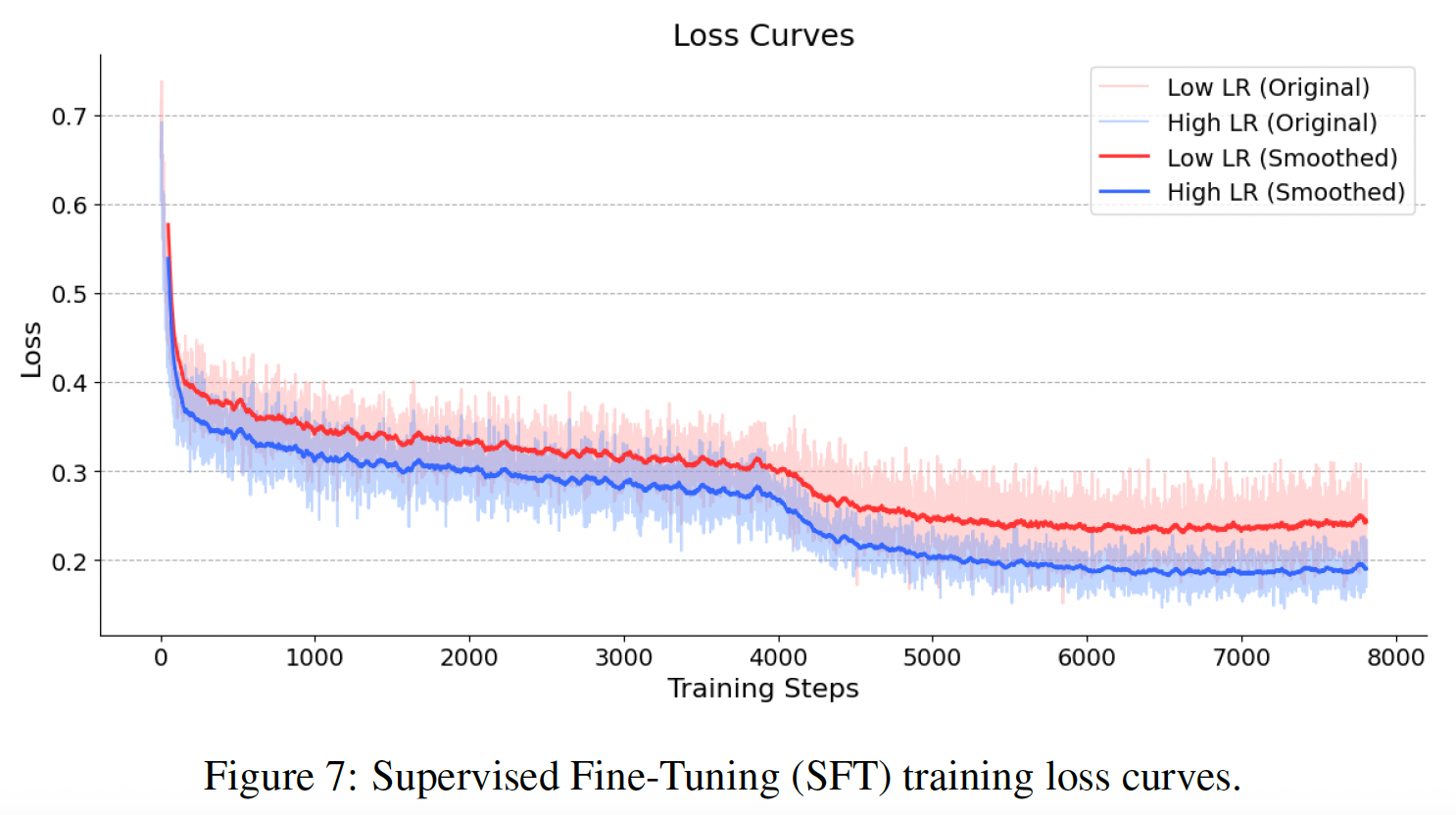
Compared to traditional SFT, we find that supervised fine-tuning on long-form reasoning tasks leads
to a pattern shift. To achieve stable convergence, this stage requires a larger learning rate and batch size.
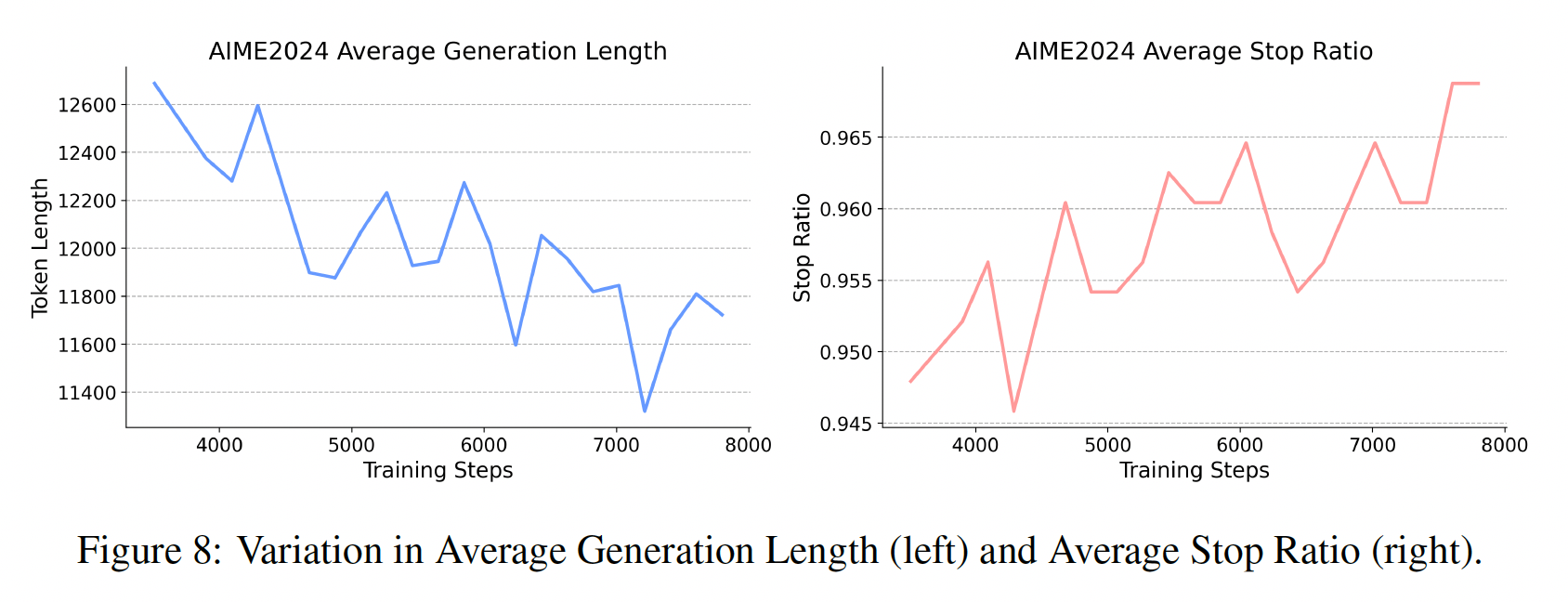
At the early stages of training, the model tends to generate excessively long outputs with a low stop ratio. As training progresses, we observe a consistent decrease in average generation length alongside a steady increase in stop ratio. This trend indicates that the model is gradually learning the structural and semantic patterns inherent in long-form reasoning prompts.
Reinforcement Learning#
We observe that selecting training queries of appropriate difficulty plays a crucial role. Prior to RL, we filter our math and code queries based on their pass rates obtained from the SFT model: we retain only those queries with pass rates strictly between 0 and 1.
Our RL pipeline consists of two stages. When the model’s performance plateaus in the first stage,
we transition to the second stage. In Stage 2, we remove all math and code queries that the model
answered correctly with 100% accuracy in Stage 1, and supplement the training set with 15k general
chat and 5k instruction-following data to improve broader generalization.
We adapt Group Relative Policy Optimization as our training algorithm. The training is configured as follows:
No KL Constraint.
Handling Overlong Responses with Zero Advantages.
Strict on-policy training.