
VAPO#
Note
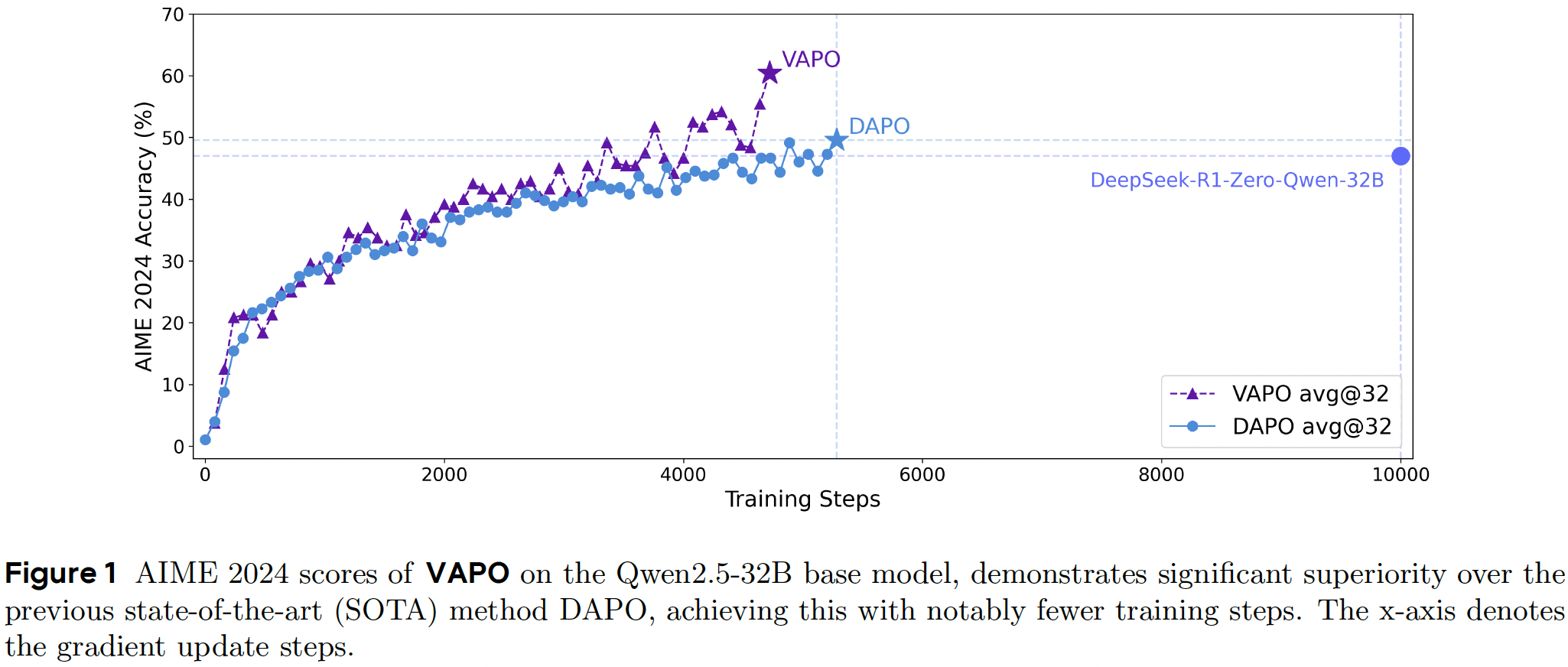
We present VAPO, Value-model-based Augmented Proximal Policy Optimization framework for
reasoning models, a novel framework tailored for reasoning models within the value-model-based
paradigm.
We argue that value-model-based
approaches possess a higher performance ceiling if the challenges in training value models can be addressed:
Value models enable
more precise credit assignmentby accurately tracing the impact of each action on subsequent returns, facilitating finer-grained optimization.In contrast to the advantage estimates derived from Monte Carlo methods in value-model-free approaches, value models can provide
lower-variance value estimatesfor each token.Furthermore, a well-trained value model exhibits inherent generalization capabilities.
Mitigating Value Model Bias over Long Sequences#
Initializing the value model with a reward model introduces significant
initialization bias. The reward
model is trained to score on the <EOS> token, incentivizing it to assign lower scores to earlier tokens due to
their incomplete context. In contrast, the value model estimates the expected cumulative reward for all tokens
preceding <EOS> under a given policy. During early training phases, given the backward computation of GAE,
there will be a positive bias at every timestep \(t\) that accumulates along the trajectory.
Value-Pretraining is proposed to mitigate the value initialization bias:
Continuously generate responses by sampling from a fixed policy, for instance, \(\pi_{\text{SFT}}\), and update the value model with Monte-Carlo return.
Train the value model until key training metrics, including value loss and explained variance, attain sufficiently low values.
Decoupled-GAE decouples the advantage computation for the value and the policy. For value updates, it is recommended to compute the value-update target with \(\lambda_{\text{critic}} = 1.0\). This choice results in an unbiased gradient-descent optimization, effectively addressing the reward-decay issues in long CoT tasks. For policy updates, using a smaller \(\lambda_{\text{policy}}\) is advisable to accelerate policy convergence under computational and time constraints.
Managing Heterogeneous Sequence Lengths during Training#
Length-Adaptive GAE aims to ensure a more uniform distribution of TD-errors across both short and long sequences. We design the sum of the coefficients \(\lambda_{\text{policy}}\) to be proportional to the output length \(l\):
which result in :
Token-Level Policy Gradient Loss. Where all tokens within a single training batch are assigned uniform weights, thereby enabling the problems posed by long sequences to be addressed with enhanced efficiency.
Dealing with Sparsity of Reward Signal in Verifier-based Tasks#
Clip-Higher increase the value of \(\epsilon_{\text{high}}\) to leave more room for the increase of low-probability tokens.
Positive Example LM Loss is designed to enhance the utilization efficiency of positive samples during RL training process. In the context of RL for complex reasoning tasks, some tasks demonstrate remarkably low accuracy, with the majority of training samples yielding incorrect answers. To address this challenge, we adopt an imitation learning approach by incorporating an additional negative log-likelihood (NLL) loss for the correct outcomes sampled during RL training:
where \(\tau\) denotes the set of correct answers. The final NLL loss is combined with the policy gradient loss through a weighting coefficient \(\mu\):
Group-Sampling reduces the number of distinct prompts per batch and redirects computational resources toward repeated generations. We observed that it is marginally better than sample each prompt only once.