Magicoder#
Note
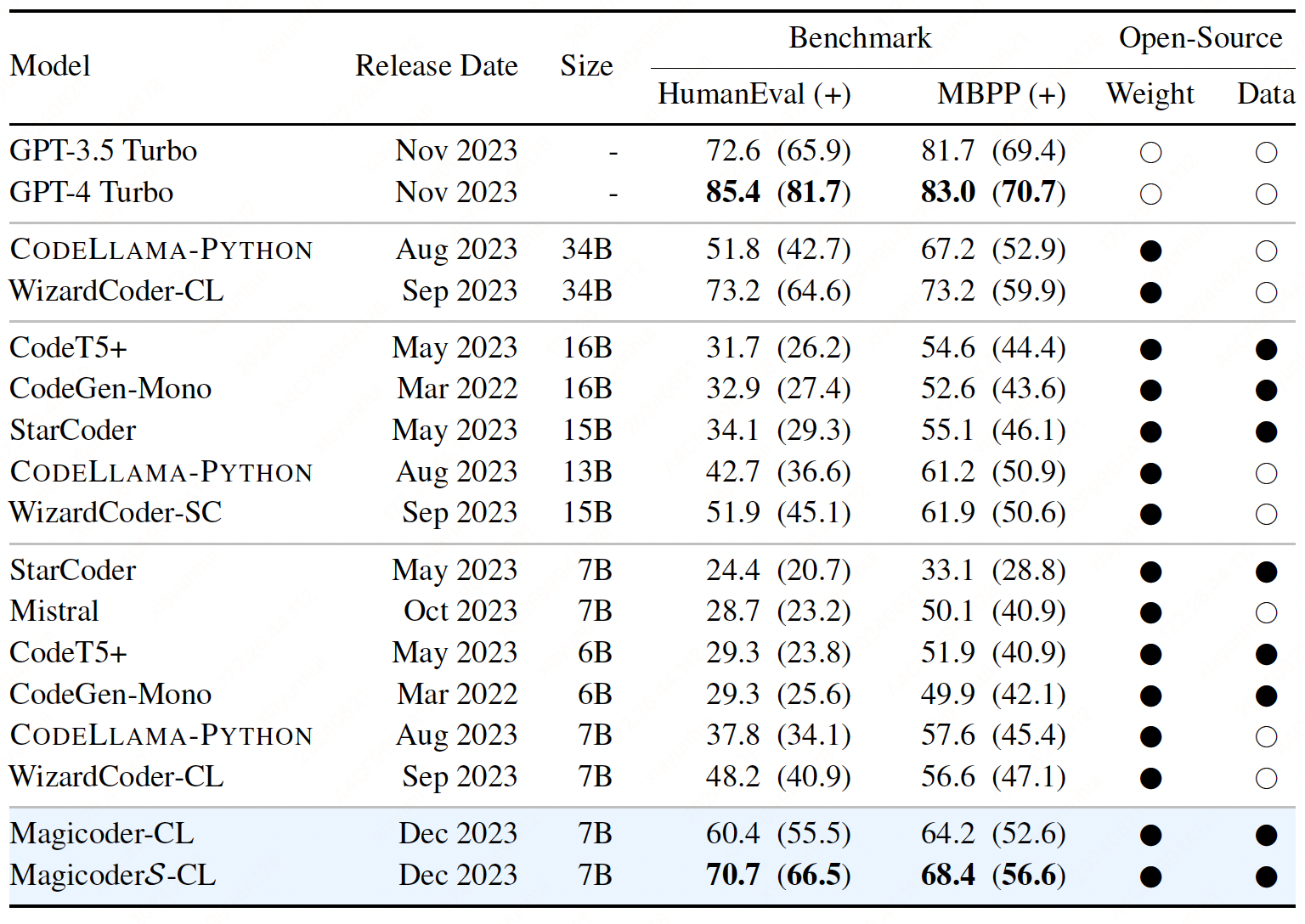
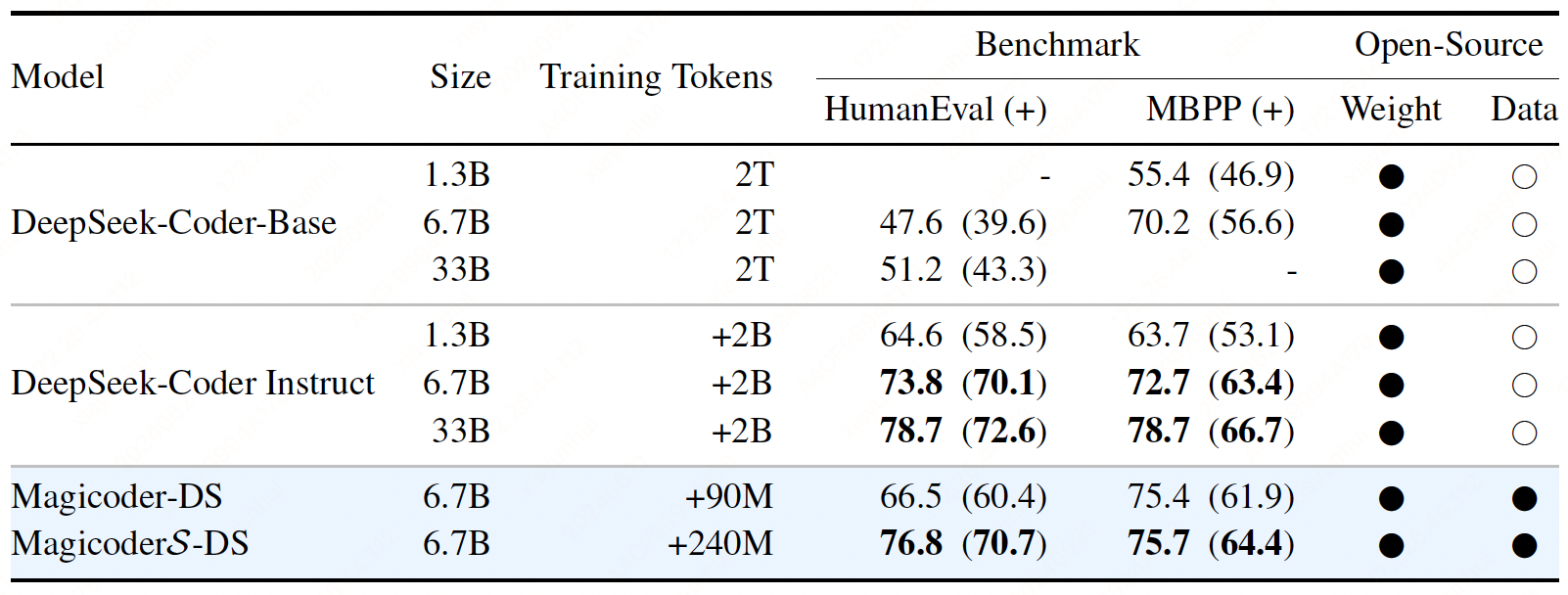
We introduce Magicoder, a series of LLMs for code that significantly closes the gap with top code models while having no more than 7B parameters. Magicoder models are trained on 75K synthetic instruction data using OSS-INSTRUCT, a novel approach to enlightening LLMs with open-source code snippets to generate high-quality instruction data for code.
Introduction#
To further push the boundaries of code generation with open source LLMs, SELF-INSTRUCT is adopted to bootstrap the instruction-following ability of LLMs. In the realm of code, practitioners commonly devise synthetic coding instructions using a stronger teacher model (e.g., ChatGPT and GPT-4) and then finetune a weaker student model (e.g., CODELLAMA) with the generated data to distill the knowledge from the teacher. For example, Code Alpaca consists of 20K automatically generated code instructions by applying SELF-INSTRUCT on ChatGPT using 21 seed tasks. To further enhance the coding abilities of LLMs, Code Evol-Instruct employs various heuristics to increase the complexity of seed code instructions (Code Alpaca).
While these data generation methods can effectively improve the instruction-following capability of an LLM, they rely on a narrow range of predefined tasks or heuristics under the hood.

OSS-INSTRUCT leverages a powerful LLM to automatically generate new coding problems by drawing inspiration from any random code snippets collected from the open source. In the end, we generate 75K synthetic data to finetune CODELLAMA-PYTHON-7B, resulting in Magicoder-CL. While being simple and effective, OSS-INSTRUCT is orthogonal to existing data generation methods, and they can be combined to further push the boundaries of the models’ coding capabilities. Therefore, we continually finetune Magicoder-CL on an open-source Evol-Instruct with 110K entries, producing MagicoderS-CL.
OSS-INSTRUCT: Instruction Tuning from Open Source#
OSS-INSTRUCT is powered by seed code snippets that can be easily collected from open source. In
this work, we directly adopt starcoderdata as our seed corpus, a filtered version of The Stack dataset that StarCoder is trained on.
For each code document from the corpus, we randomly extract 1–15 consecutive lines as the seed snippet for the model to gain inspiration from and produce coding problems. In total, we collected 80K initial seed snippets from 80K code documents. Then, each collected seed code snippet is applied to the prompt template shown below, which a teacher model takes as input and outputs both a coding problem and its solution.

Implementation Details#
Data generation We use gpt-3.5-turbo-1106 as the foundation model to do OSS-INSTRUCT. We perform greedy decoding to maximize
the consistency between the generated problems and solutions.
Training We employ CODELLAMA-PYTHON-7B and DeepSeek-Coder-Base 6.7B as the base
LLMs. To obtain Magicoder series, we first finetune the base models on about 75K synthetic data
generated through OSS-INSTRUCT. To obtain MagicoderS,
we continue to finetune Magicoder models with the evol-codealpaca-v1 dataset, an open-source
Evol-Instruct implementation containing about 110K samples.
Evaluation#
Evaluation powered by EvalPlus.