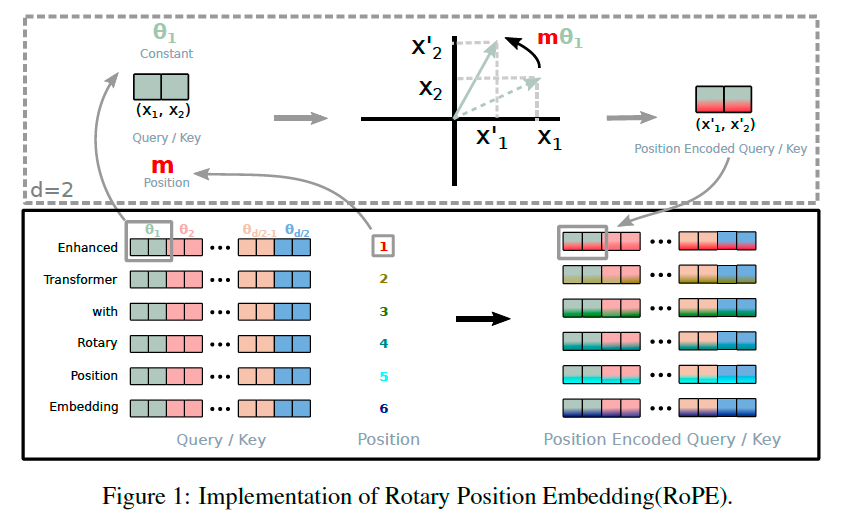
RoPE#
Note
Transformer-based language modeling usually leverages the position information of individual tokens through a self-attention mechanism. \(\mathbf{q}_{m}^{\intercal}\mathbf{k}_{n}\) typically enables knowledge transfer between tokens at different positions. In order to incorporate relative position information, we require the inner product of query \(\mathbf{q}_{m}\) and key \(\mathbf{k}_{n}\) to be formulated by a function \(g\), which takes only the word embeddings \(\mathbf{x}_{m}\), \(\mathbf{x}_{n}\), and their relative position \(m-n\) as input variables.
2D case#
Begin with \(d=2\), we make use of the property of the rotary matrix:
Let:
Then:
Tip
\( \mathbf{R}_{\theta}\mathbf{v}\) equals counterclockwise rotation of \(\mathbf{v}\) through angle \(\theta\).
General form#
In order to generalize our results in 2D to any \(\mathbf{x}_{i}\in\mathbb{R}^{d}\) where \(d\) is even, we divide the d-dimensional space into \(d/2\) sub-spaces:
is the rotary matrix with pre-defined parameters \(\Theta = \{\theta_{i}=10000^{-2(i-1)/d},i\in[1,2,\dots,d/2]\}\). RoPE encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation.
Tip
where 10000 is the RoPE base, \(\theta_{1}\) corresponds to the highest frequency. Smaller \(i\) encodes high frequency information (information nearby).