
Acecoder#
Note
Synthesizes large-scale reliable question and tests for code generation using a fully automated pipeline!
ACECODE-87K#
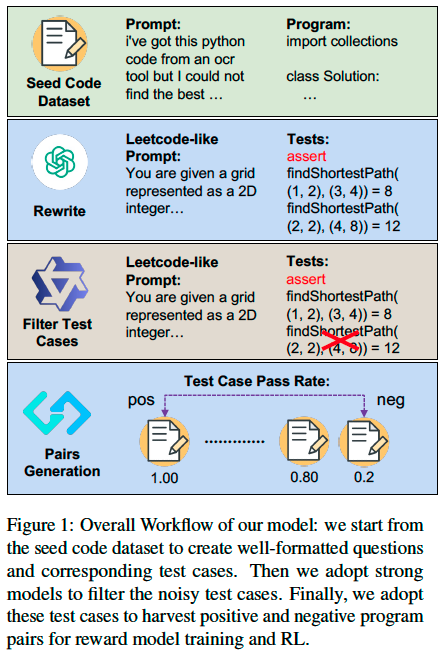
Test Case Synthesis from Seed Dataset#
We start
from existing coding datasets with provided question
\(x\) and corresponding program \(y\). Specifically,
we combine Magicoder-Evol-Instruct, Magicoder- OSS-Instruct-75K, and StackPyFunction as our
seed dataset.
We only keep the questions written in Python that contain either a function or a class, resulting in a total of 124K entries. We find that these datasets contain highly noisy questions that cannot be easily evaluated using test cases. Therefore, we feed every question-solution pair \((x, y)\) into a GPT-4o-mini to propose a refined LeetCode-style question \(x_r\) with highly structured instructions. Meanwhile, we also prompt it to ‘imagine’ around 20 test cases \((t_1, \dots, t_m)\) for each refined coding question \(x_r\) based on its understanding of the expected behavior of the desired program.

Test Case Filtering#
we facilitated a stronger coder model Qwen2.5- Coder-32B-Instruct as a proxy to perform quality control. Specifically, we prompt it for each \(x_r\) to generate a program \(y'\). We removed all test cases \(t_i\) where the generated solution program \(y'\) could not pass.
Preference Pairs Construction#
we sample programs \((y_1, \dots, y_n)\) from existing models w.r.t \(x_r\) and utilize the test-case pass rate to distinguish positive and negative programs. Our selection rules are:
This is to ensure the preferred program has at least a 0.8 pass rate to make sure it represents a more correct program. Also, we find that many sampled programs with 0 pass rates can be caused by some small syntax errors or some Python packaging errors during evaluation. We chose not to include them as the preference pair to make sure our constructed datasets represent only the preference based on the valid pass rate.