
SELF-INSTRUCT#
Note
We introduce SELF-INSTRUCT, a semi-automated process for instruction-tuning a pretrained LM using instructional signals from the model itself. The overall process is an iterative bootstrapping algorithm, which starts off with a limited (e.g., 175 in our study) seed set of manually-written tasks that are used to guide the overall generation.
In the first phase, the model is prompted to generate instructions for new tasks. This step leverages the existing collection of instructions to create more broad-coverage instructions that define (often new) tasks.
Given the newly-generated set of instructions, the framework also creates input-output instances for them, which can be later used for supervising the instruction tuning.
Finally, various heuristics are used to automatically filter low-quality or repeated instructions, before adding the remaining valid tasks to the task pool.
This process can be repeated for many iterations until reaching a large number of tasks.
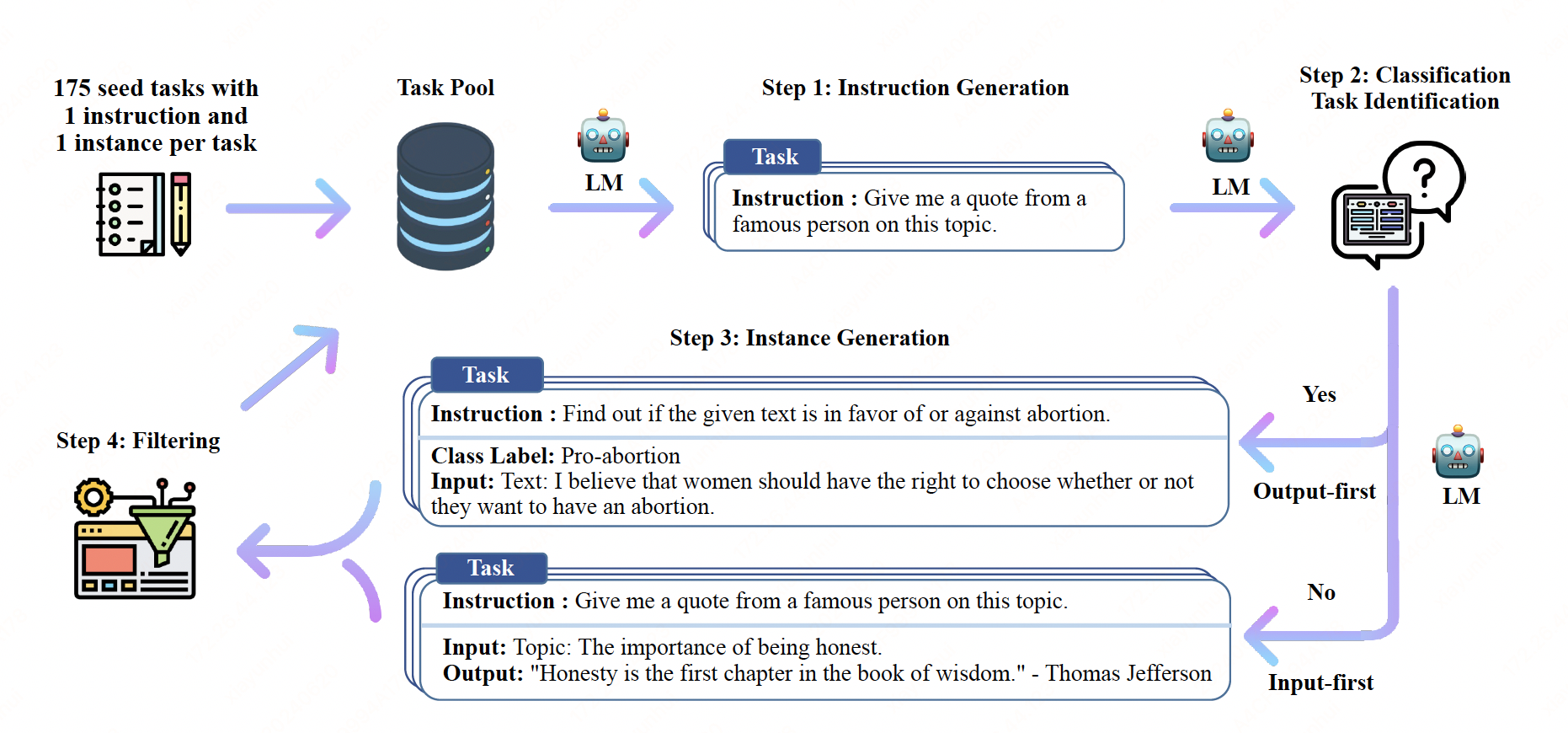
Instruction Generation#

Classification Task Identification#
Because we need two different approaches for classification and non-classification tasks, we next identify whether the generated instruction represents a classification task or not in a few-shot way.
Instance Generation#
Given the instructions and their task type, we generate instances for each instruction independently.
A natural way to do this is the Input-first Approach, where we can ask an LM to come up with the input fields first based on the instruction, and then produce the corresponding output.
However, we found that this approach can generate
inputs biased toward one label, especially for
classification tasks. Therefore,
we additionally propose an Output-first Approach for classification tasks, where we first generate
the possible class labels, and then condition the
input generation on each class label.
Filtering and Postprocessing#
To encourage diversity, a new instruction is added to the task pool only when its ROUGE-L similarity with any existing instruction is less than 0.7.
Tip
ROUGE-L focuses on measuring the longest common subsequence (LCS) between the two texts. ROUGE-L combines two scores to produce a final similarity score:
Precision = LCS_length / Candidate_length
Recall = LCS_length / Reference_length
The final ROUGE-L score, balancing precision and recall through F1-Score.
Finetuning the LM to Follow Instructions#
After creating large-scale instruction data, we use it to finetune the original LM (i.e., SELF-INSTRUCT, total 52K instructions and 82K instances).
Tip
We concatenate the instruction and instance
input as a prompt and train the model to
generate the instance output in a standard supervised
way. To make the model robust to different
formats, we use multiple templates to encode the instruction and instance input together. For example,
the instruction can be prefixed with “Task:” or
not, the input can be prefixed with “Input:” or not,
“Output:” can be appended at the end of the prompt
or not, and different numbers of break lines can be
put in the middle, etc.