
GPT#
Note
We demonstrate that large gains on a wide range of NLP tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task.
Unsupervised pre-training#
Given an unsupervised corpus of tokens \(\mathcal{U} = \{u_1,\dots,u_n\}\), we use a standard language modeling objective to maximize the following likelihood:
where \(k\) is the size of the context window, and the conditional probability \(P\) is modeled using a neural network with parameters \(\Theta\). These parameters are trained using stochastic gradient descent.
In our experiments, we use a multi-layer Transformer decoder for the language model, which is a variant of the transformer. This model applies a multi-headed self-attention operation over the input context tokens followed by position-wise feedforward layers to produce an output distribution over target tokens:
where \(U\) is the context vector of tokens, \(n\) is the number of layers, \(W_e\) is the token embedding matrix, and \(W_p\) is the position embedding matrix.
Supervised fine-tuning#
After training the model with the language modeling objective, we adapt the parameters to the supervised target task. We assume a labeled dataset \(\mathcal{C}\), where each instance consists of a sequence of input tokens \(x^{1},\dots,x^{m}\), along with a label \(y\). The inputs are passed through our pre-trained model to obtain the final transformer block’s activation \(h_{l}^{m}\), which is then fed into an added linear output layer with parameters \(W_y\) to predict \(y\):
This gives us the following objective to maximize:
We additionally found that including language modeling as an auxiliary objective to the fine-tuning helped learning by (a) improving generalization of the supervised model, and (b) accelerating convergence. Specifically, we optimize the following objective (with weight \(\lambda\)):
Overall, the only extra parameters we require during fine-tuning are \(W_{y}\), and embeddings for delimiter tokens.
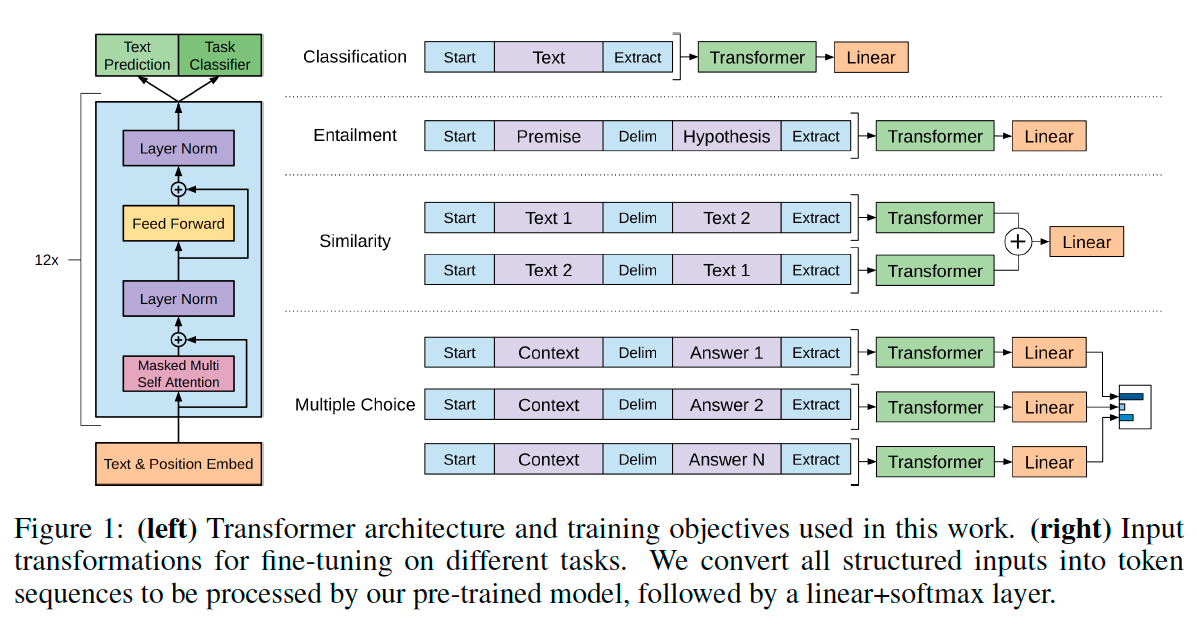
Tip
Why decoder-only:
Autoregressive Generation.
Simplicity and Scalability.
Training Efficiency.