
Not All Correct Answers Are Equal#
Note
In this work, we conduct
a large-scale empirical study on reasoning data distillation by collecting verified
outputs from three state-of-the-art teacher models—AM-Thinking-v1, Qwen3-
235B-A22B, and DeepSeek-R1—on a shared corpus of 1.89 million queries.
We construct three parallel datasets and analyze their distributions, revealing that
AM-Thinking-v1-distilled data exhibits greater token length diversity and lower
perplexity.
Data#
Data Collection and Query Processing#
Code Generation: Datasets aimed at enhancing code synthesis and programmatic problemsolving
abilities, including PRIME, DeepCoder, KodCode.
Filtering:
Queries with a high Unicode character ratio were discarded to eliminate corrupted or meaningless samples.
Incomplete or empty queries were excluded.
Instances containing URLs or tabular structures were filtered out to reduce noise and hallucination risk.
Data Distilling#
For every model,
the distillation process was repeated on the same query until the generated response satisfied the verification criterion (i.e., the verification score ≥ 0.9).
Automatic Verification and Scoring
Code Generation: Each code response was validated in a sandbox environment using up to 10 test cases (assert and input-output for Python; input-output for C++), with the verification score reflecting the pass rate.
Quality Assurance Measures
Perplexity-based Filtering: We computed perplexity scores using a strong 32B language model, with each model employing a different threshold.
High-Frequency Ngram Filtering: 20-token ngrams occurring more than 20 times were identified and removed to reduce template-like redundancy.
Data Analysis#
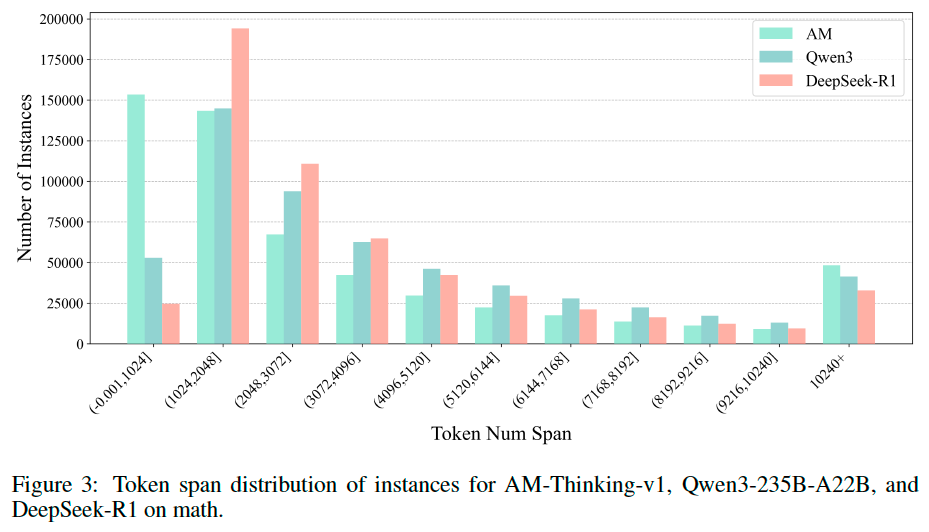
Experiments#
Training Configuration#
Training is conducted based on the Qwen2.5-32B base model. All three models are trained with a learning rate of 8e-5, a maximum sequence length of 32k (using sequence packing), and a global batch size of 64 for 2 epochs. Samples longer than 32k tokens are excluded.
Benchmarks and Evaluation Setup#
All benchmarks were evaluated under uniform conditions. The generation length was capped at
49,152 tokens. For stochastic decoding, we consistently adopted a temperature of 0.6 and top-p of
0.95 across applicable tasks.
Followed by AM-Thinking-v1, a unified system prompt was employed across all tasks to standardize output format and encourage reasoning:
You are a helpful assistant. To answer the user’s question,
you first think about the reasoning process and then provide
the user with the answer. The reasoning process and answer
are enclosed within <think> </think> and <answer> </answer>
tags, respectively, i.e., <think> reasoning process here
</think> <answer> answer here </answer>.
Results and Analysis#
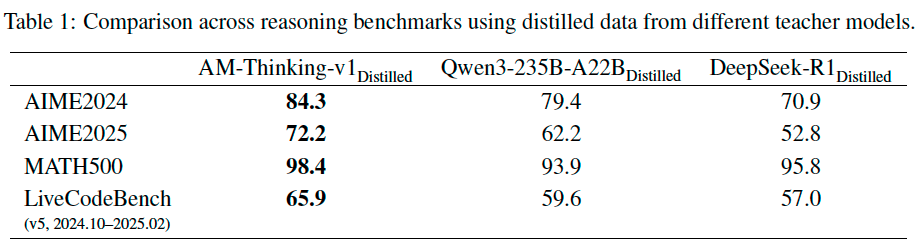
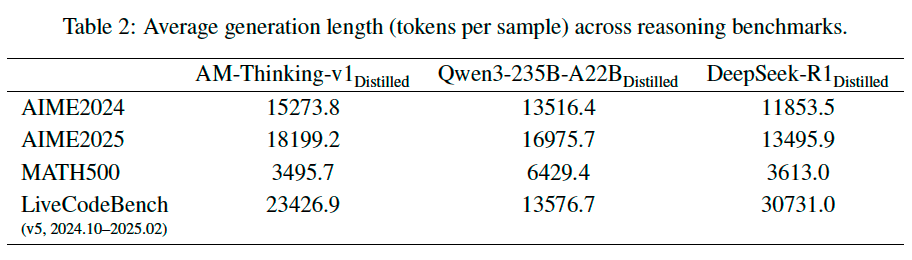
As shown in Table 1, the model distilled from AM-Thinking-v1 consistently achieves the highest accuracy across all benchmarks. To better understand model behavior (Table 2), we analyze the average generation length per sample across benchmarks. The adaptive generation pattern of the AM-distilled model suggests that the AM-distilled model can better modulate its output length based on task complexity—generating more detailed solutions when needed while remaining concise on simpler problems.
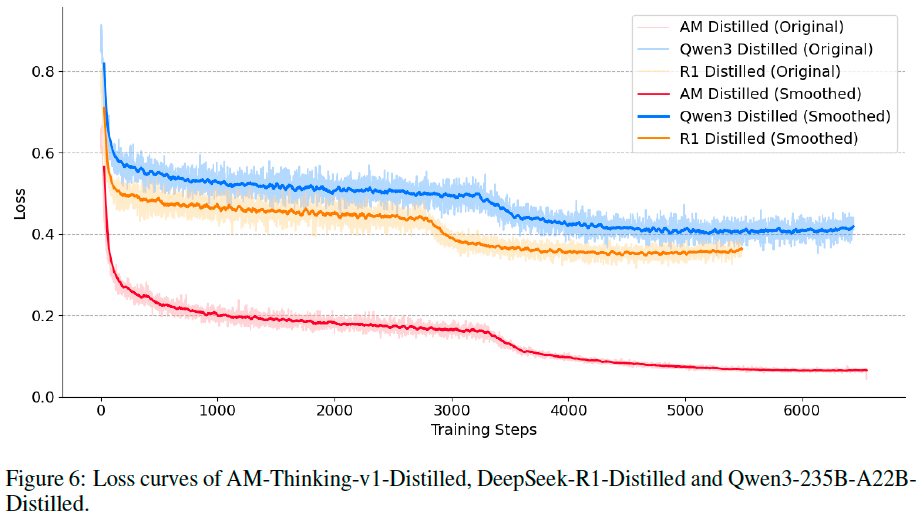
We further compare training dynamics by examining the loss curves shown in Figure 6. The AM-Thinking-v1-Distilled maintains a consistently lower training loss than its Qwen3-235B-A22B-Distilled and DeepSeek-R1-Distilled counterparts throughout the optimization process. This observation supports the notion that the AM-Thinking-v1 dataset provides more learnable, coherent, and high-quality supervision signals for the base model.