
GSPO#
Note
Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization.
Motivation#
The principle of importance sampling is to estimate the expectation of a function \(f\) under a target distribution \(\pi_{\text{tar}}\) by re-weighting samples drawn from a behavior distribution \(\pi_{\text{beh}}\):
This relies on averaging over multiple samples (\(N \gg 1\)) from the behavior distribution \(\pi_{\text{beh}}\) for the importance weight \(\frac{\pi_{\text{tar}}(z)}{\pi_{\text{beh}}(z)}\) to effectively correct for the distributional mismatch.
In contrast, GRPO applies the importance weight at each token position \(t\). Since this weight is based on a single sample \(y_{i,t}\) from each next-token distribution \(\pi_{\theta_{\text{old}}}(\cdot|x, y_{i,<t})\), it fails to perform the intended distribution-correction role.
Tip
A core principle: the unit of optimization objective should match the unit of reward.
GSPO: Group Sequence Policy Optimization#
We propose the Group Sequence Policy Optimization (GSPO) algorithm. GSPO employs the following sequence-level optimization objective:
where we adopt the group-based advantage estimation:
and define the importance ratio \(s_{i}(\theta)\) based on sequence likelihood:
Therefore, GSPO applies clipping to entire responses instead of individual tokens to exclude the overly “off-policy” samples from gradient estimation, which matches both the sequence-level rewarding and optimization.
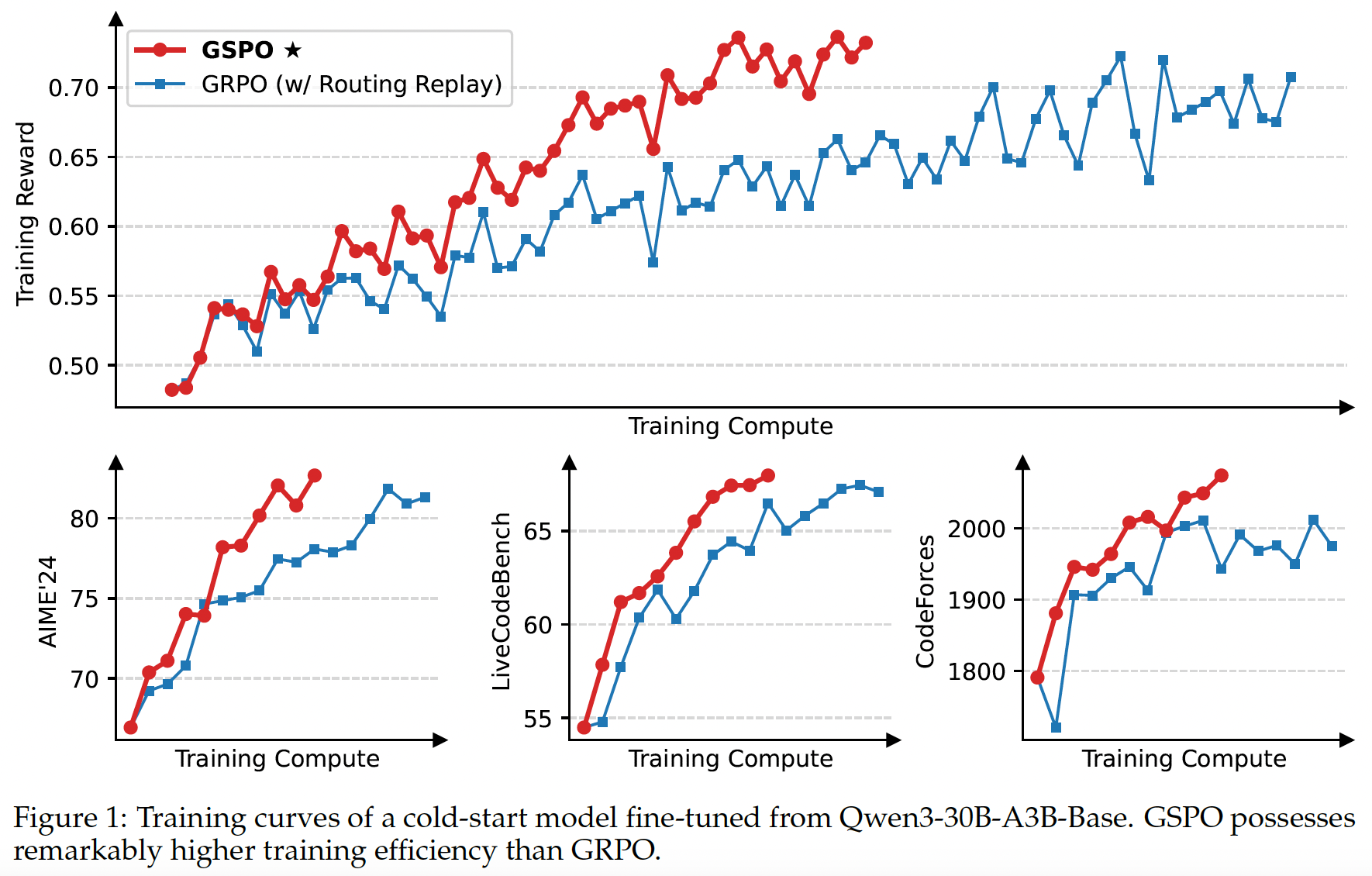
Benefit of GSPO for MoE Training#
Background Compared to the RL training of dense models, the sparse activation nature of MoE models introduces unique stability challenges. After one or more gradient updates, the experts activated for the same response can change significantly. This phenomenon, which becomes more prominent in deeper MoE models, makes the token-level importance ratios fluctuate drastically and further invalidates them.
Our Previous Approach To tackle this challenge, we previously employed the Routing Replay training strategy.
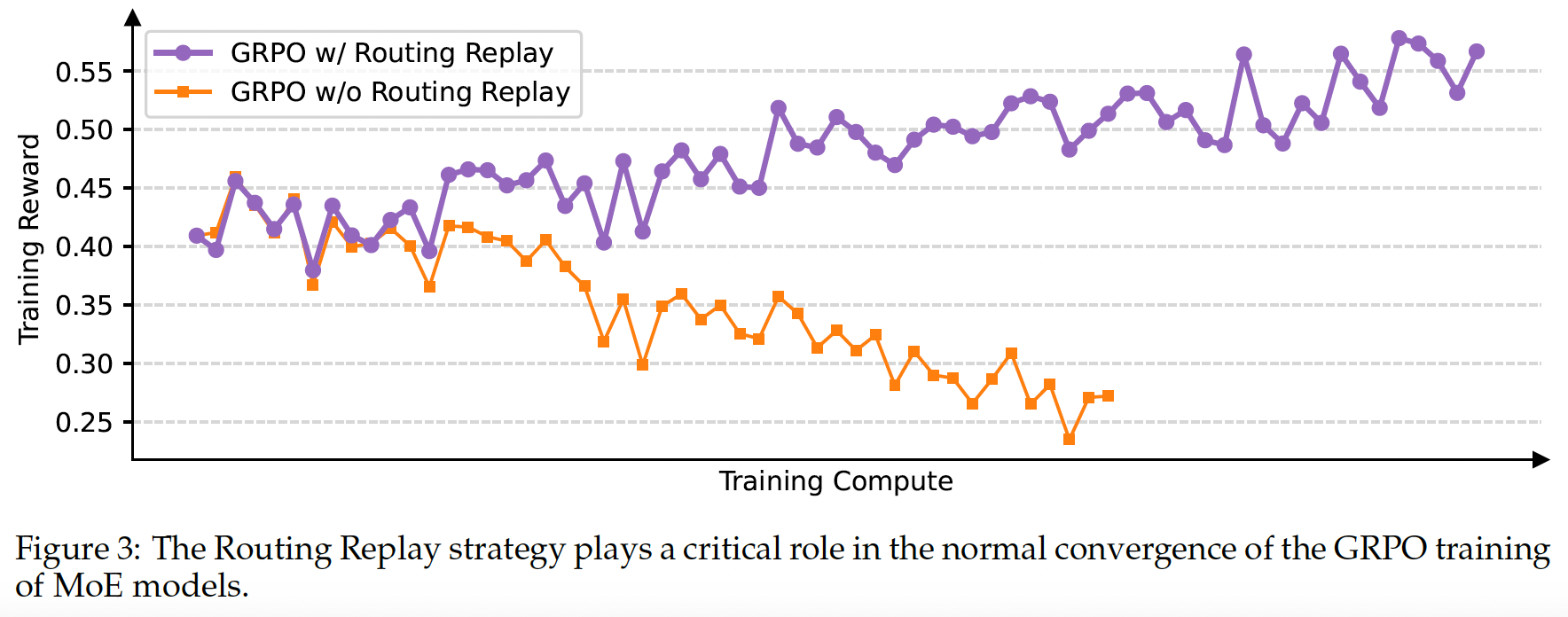
Benefit of GSPO GSPO focuses
only on the sequence likelihood and is not sensitive to the individual token likelihood. Since the MoE model always maintains its language modeling capability, the sequence
likelihood will not fluctuate drastically. In summary, GSPO fundamentally resolves the expert-activation
volatility issue in MoE models.