
DeepSeek-R1#
Note
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities.
DeepSeek-R1-Zero#
Reinforcement Learning Algorithm. GRPO
Reward Modeling#
The reward is the source of the training signal, which decides the optimization direction of RL. To train DeepSeek-R1-Zero, we adopt a rule-based reward system that mainly consists of two types of rewards:
Accuracy rewards: The accuracy reward model evaluates whether the response is correct.
Format rewards: In addition to the accuracy reward model, we employ a format reward model that enforces the model to put its thinking process between
\<think>and\</think\>tags.
We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process.
Training Template#
To train DeepSeek-R1-Zero, we begin by designing a straightforward template that guides the base model to adhere to our specified instructions.

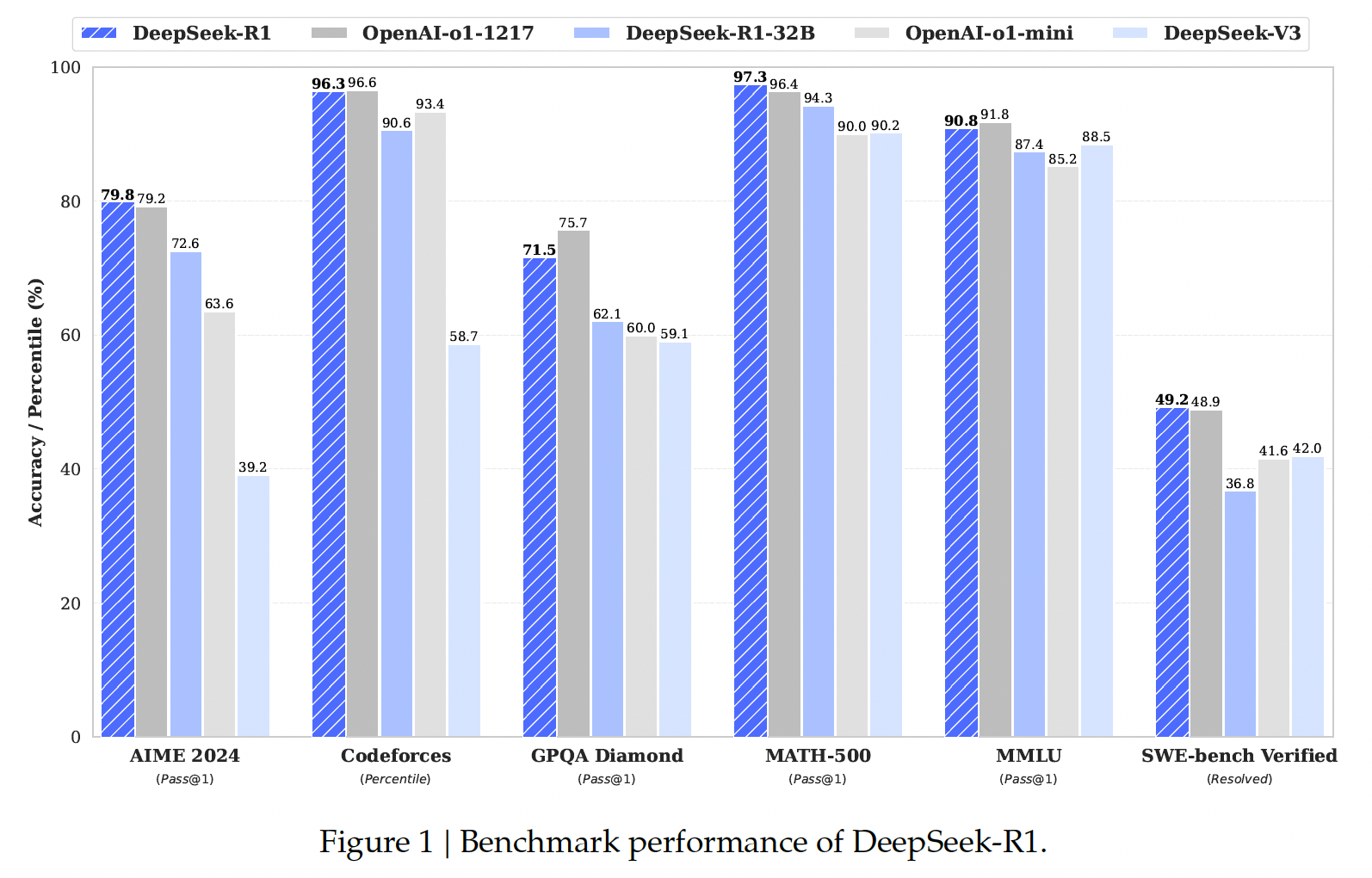
Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero#
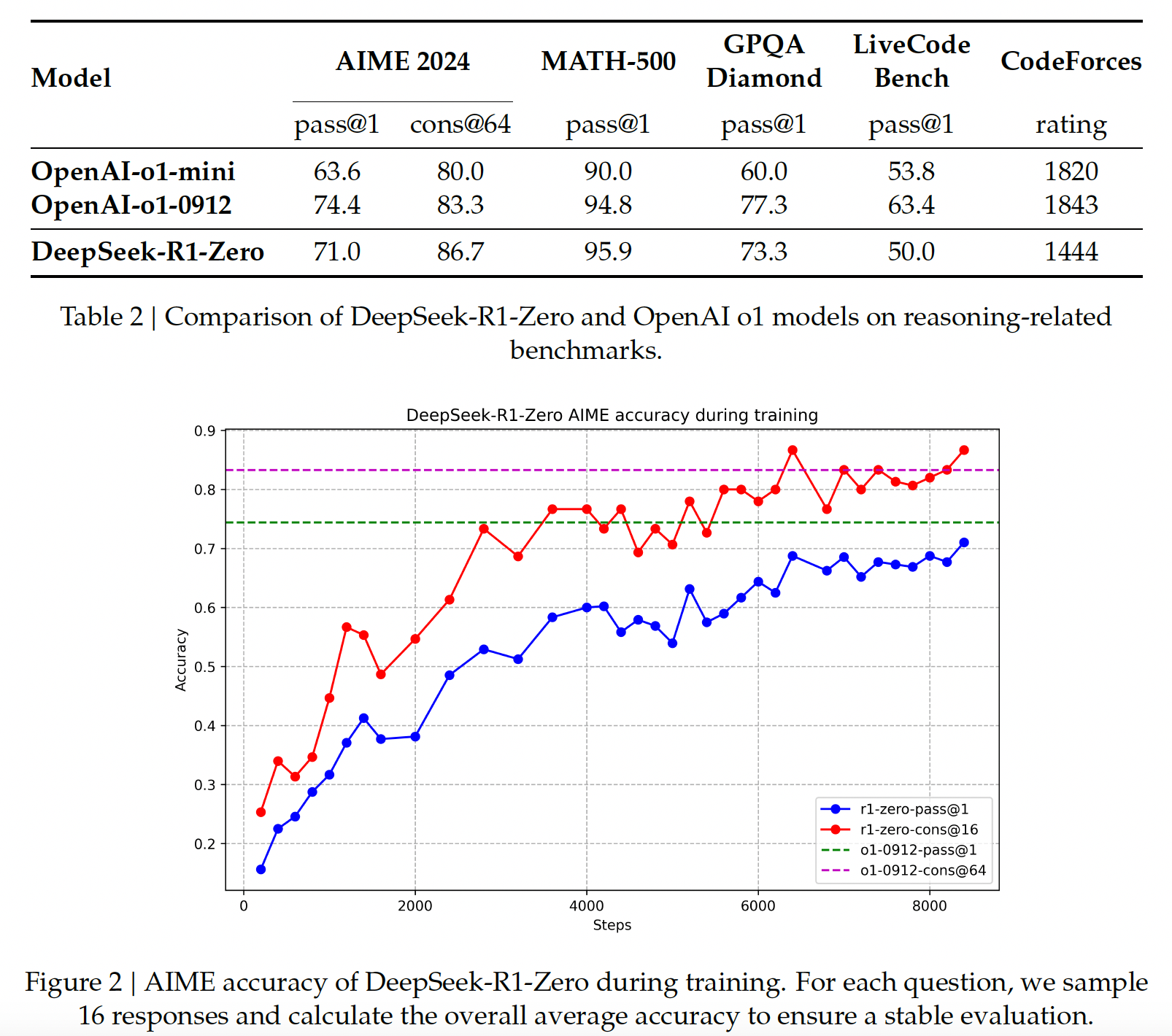
where cons@64 (consensus) denote majority vote using 64 samples.
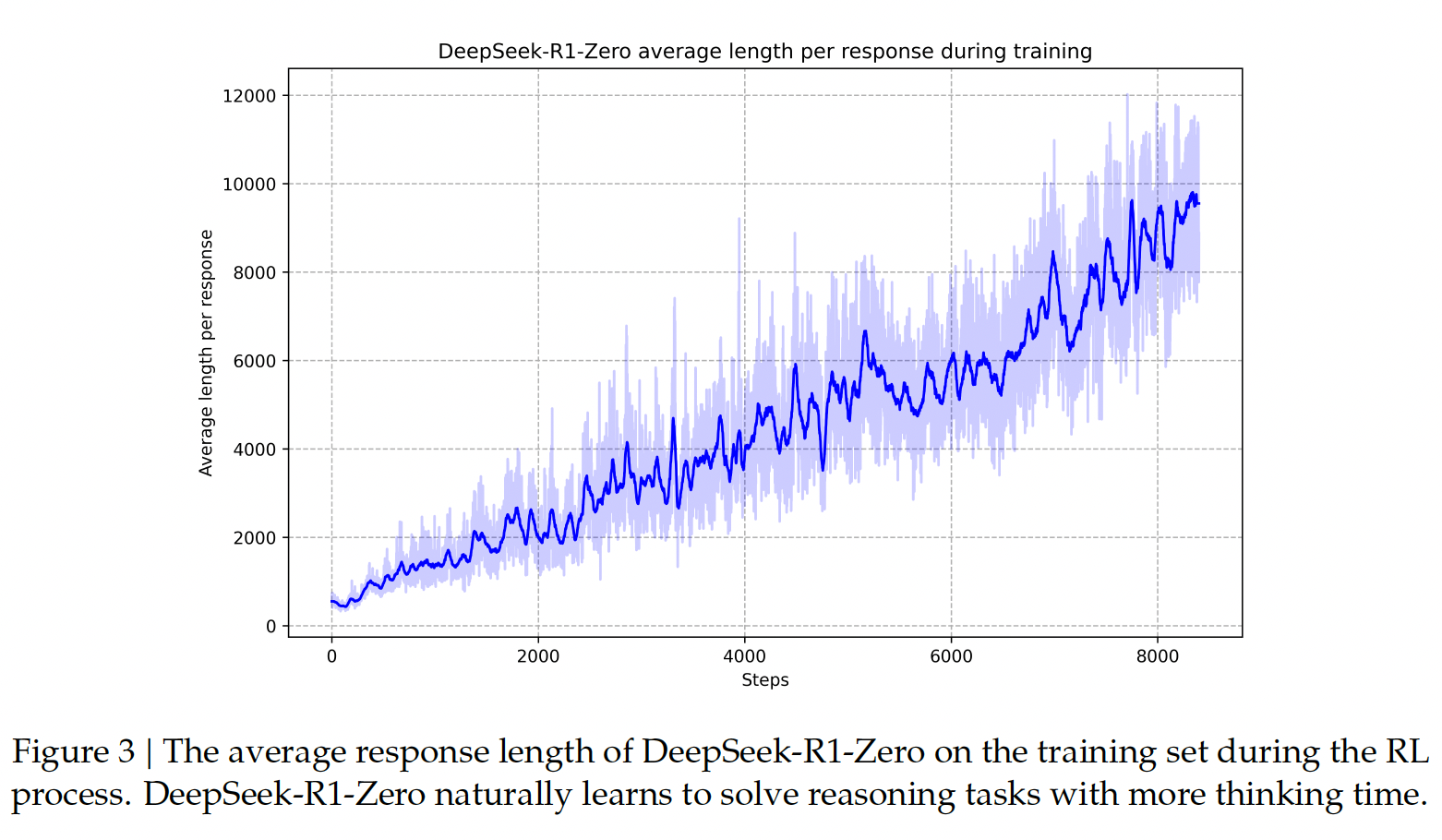
Self-evolution Process of DeepSeek-R1-Zero As depicted in Figure 3, the thinking time of DeepSeek-R1-Zero shows consistent improvement throughout the training process. This improvement is not the result of external adjustments but rather an intrinsic development within the model. DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation.
Aha Moment of DeepSeek-R1-Zero
A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”. This moment, as illustrated occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach.
Drawback of DeepSeek-R1-Zero Although DeepSeek-R1-Zero exhibits strong reasoning capabilities and autonomously develops unexpected and powerful reasoning behaviors, it faces several issues. For instance, DeepSeek-R1-Zero struggles with challenges like poor readability, and language mixing. To make reasoning processes more readable and share them with the open community, we explore DeepSeek-R1.
DeepSeek-R1#
To make reasoning processes more readable, we design a pipeline to train DeepSeek-R1. The pipeline consists of four stages, outlined as follows.
Cold Start#
For DeepSeek-R1, we construct and collect a small amount of long CoT data to fine-tune the DeepSeek-V3-Base as the starting point for RL.
Reasoning-oriented Reinforcement Learning#
After fine-tuning DeepSeek-V3-Base on the cold start data, we apply the same large-scale reinforcement learning training process as employed in DeepSeek-R1-Zero.
Rejection Sampling and Supervised Fine-Tuning#
Reasoning data. We curate reasoning prompts and generate reasoning trajectories by performing rejection sampling from the checkpoint from the above RL training.
Non-Reasoning data. For non-reasoning data, such as writing, factual QA, self-cognition, and translation, we adopt the DeepSeek-V3 pipeline and reuse portions of the SFT dataset of DeepSeek-V3.
We fine-tune DeepSeek-V3-Base for two epochs.
Reinforcement Learning for all Scenarios#
We train the model using a combination of reward signals and diverse prompt distributions.
For reasoning data. We adhere to the methodology outlined in DeepSeek-R1-Zero, which utilizes rule-based rewards to guide the learning process in math, code, and logical reasoning domains.
For general data. we resort to reward models to capture human preferences in complex and nuanced scenarios.