
Math & Science Benchmarks#
MATH#
The MATH dataset consists of problems from mathematics competitions including the AMC 10, AMC 12, AIME, and more. These competitions span decades and assess the mathematical problem-solving ability of the best young mathematical talent in the United States. Unlike most prior work, most problems in MATH cannot be solved with a straightforward application of standard K-12 mathematics tools.
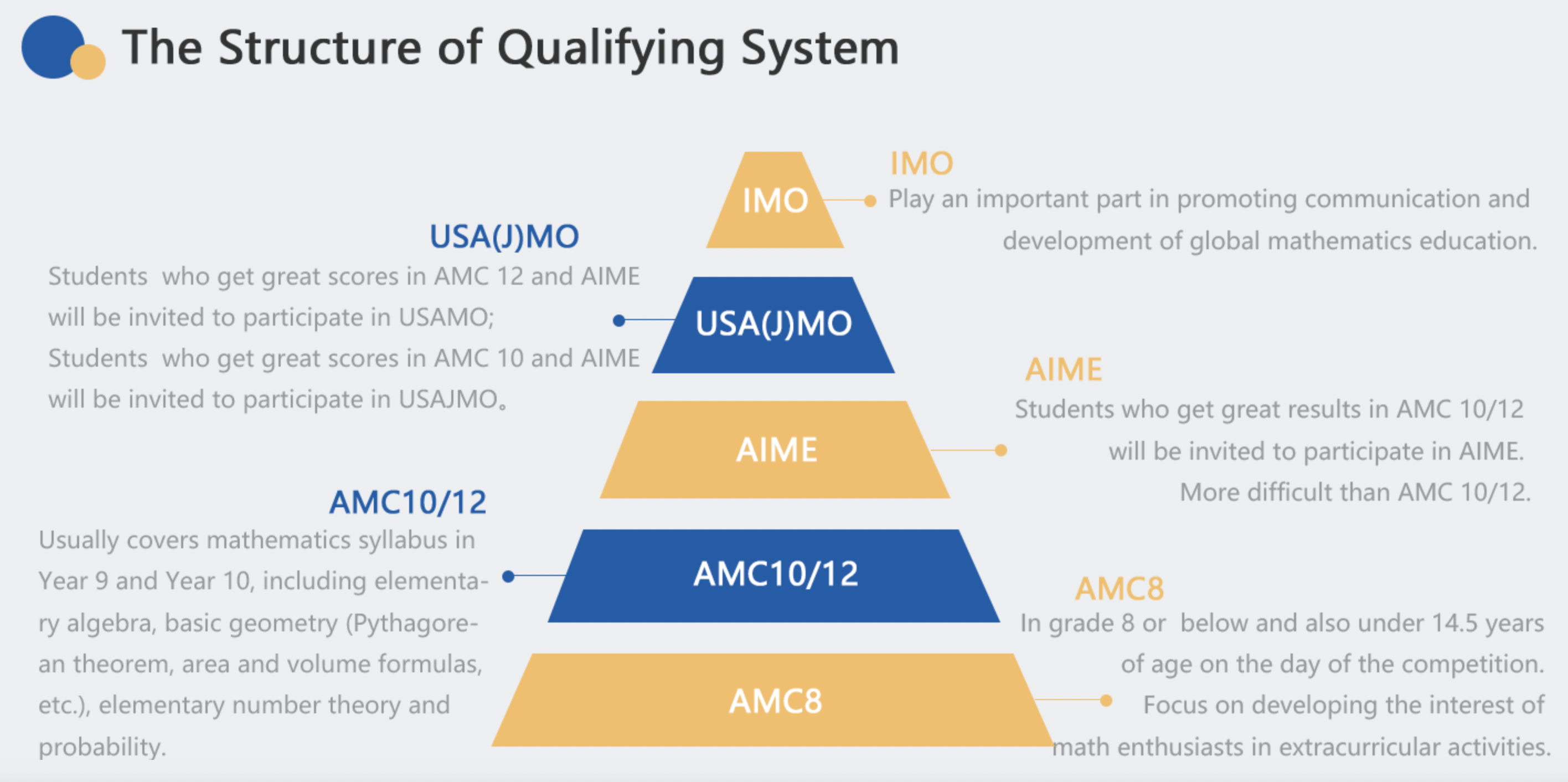
The Mathematics Aptitude Test of Heuristics dataset, abbreviated MATH, has 12;500 problems (7;500 training and 5;000 test). With this many training problems, models can learn many useful heuristics for problem solving. Each problem has a step-by-step solution and a final boxed answer.

Formatting. Problems and solutions are consistently formatted using LATEX and the Asymptote vector graphics language. To assess models using exact match, we force the final boxed answers to follow consistent formatting rules.
MATH 500#
This dataset contains a subset of 500 problems from the MATH benchmark that OpenAI created in their Let’s Verify Step by Step paper[LKB+23].
GSM8K#
Note
Introduced in the paper Training Verifiers to Solve Math Word Problems[CKB+21].
GSM8K consists of 8.5K high quality grade school math problems created by human problem writers. We segmented these into 7.5K training problems and 1K test problems. These problems take between 2 and 8 steps to solve, and solutions primarily involve performing a sequence of elementary calculations using basic arithmetic operations (+ - / *) to reach the final answer. A bright middle school student should be able to solve every problem.

GPQA#
GPQA is a challenging dataset of 448 multiple-choice questions written by
domain experts in biology, physics, and chemistry. We ensure that the questions are
high-quality and extremely difficult: experts who have or are pursuing PhDs in the
corresponding domains reach 65% accuracy, while highly skilled non-expert validators only
reach 34% accuracy. The questions are also
difficult for state-of-the-art AI systems, with our strongest GPT-4–based baseline
achieving 39% accuracy. The difficulty of GPQA both for skilled non-experts and frontier
AI systems should enable realistic scalable oversight experiments, which we hope
can help devise ways for human experts to reliably get truthful information from AI
systems that surpass human capabilities.
Tip
Scalable Oversight is a key research direction in the field of AI Alignment, aiming to address the challenge of how to continuously and reliably supervise the behavior of AI systems and ensure their alignment with human values when their capabilities surpass human levels.
GPQA Diamond We create GPQA Diamond (the diamond set, composed of 198 questions) is our highest quality subset which includes only questions where both experts answer correctly and the majority of non-experts answer incorrectly.