
PPO Implementation#
Note
Now that we studied the theory behind PPO, the best way to understand how it works is to implement it from scratch.
PPO implementation details#
Tip
First we will introduce some core implementation details commonly used. See The 37 Implementation Details of Proximal Policy Optimization.
Vectorized architecture#
PPO leverages an efficient paradigm known as the vectorized architecture that features a single learner that collects samples and learns from multiple environments. Below is a pseudocode:
envs = VecEnv(num_envs=N) # multiple enviroments
agent = Agent() # single learner
next_obs = envs.reset()
next_done = [0, 0, ..., 0] # of length N
for update in range(total_timesteps // (N*M)):
data = []
# ROLLOUT PHASE
for step in range(0, M):
obs = next_obs
done = next_done
action, other_stuff = agent.get_action(obs)
next_obs, reward, next_done, info = envs.step(action) # step in N enviroments
data.append([obs, action, reward, done, other_stuff]) # store data
# LEARNING PHASE
agent.learn(data, next_obs, next_done) # `len(data) = N*M`
In this architecture, PPO first initializes a vectorized environment envs that runs \(N\) (usually independent) environments either sequentially or in parallel by leveraging multi-processes.
PPO also initializes an environment done flag variable next_done to an \(N\)-length array of zeros, where its \(i\)-th element has values of 0 or 1 which corresponds to the \(i\)-th sub-environment being not done and done, respectively. If the \(i\)-th sub-environment is done (terminated or truncated) after stepping with the \(i\)-th action action[i], envs would set its returned next_done[i] to 1, auto-reset the \(i\)-th sub-environment and fill next_obs[i] with the initial observation in the new episode of the \(i\)-th environment.
Generalized Advantage Estimation#
Mini-batch Updates#
During the learning phase of the vectorized architecture, the PPO implementation shuffles the indices of the raining data of size \(N\ast M\) and breaks it into mini-batches to compute the gradient and update the policy.
Normalization of Advantages#
After calculating the advantages based on GAE, PPO normalizes the advantages by subtracting their mean and dividing them by their standard deviation. In particular, this normalization happens at the minibatch level instead of the whole batch level!
Value Function Loss Clipping#
PPO clips the value function like the PPO’s clipped surrogate objective. Given the \(V_\text{target}\) = returns = advantages + values, PPO fits the the value network by minimizing the following loss:
Shared and separate MLP networks for policy and value functions#
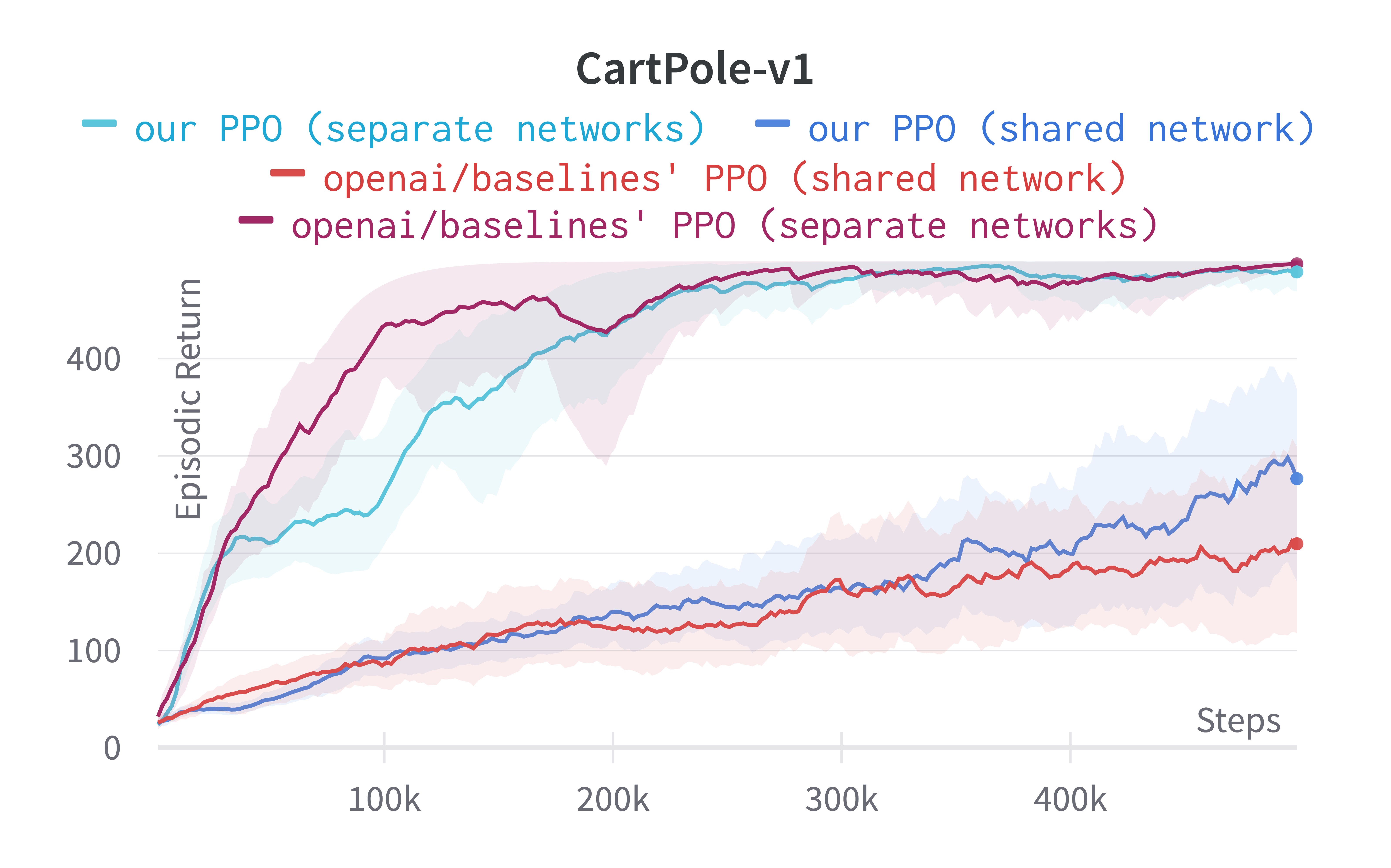
The separate-networks architecture clearly outperforms in simpler environments. The shared-network architecture performs worse probably due to the competing objectives of the policy and value functions.
PPO with CleanRL#
Args#
from dataclasses import dataclass
@dataclass
class Args:
env_id: str = "CartPole-v1"
"""the id of the environment"""
total_timesteps: int = 200000
"""total timesteps of the experiments"""
learning_rate: float = 2.5e-4
"""the learning rate of the optimizer"""
num_envs: int = 4
"""the number of parallel game environments"""
num_steps: int = 128
"""the number of steps to run in each environment per policy rollout"""
num_minibatches: int = 4
"""the number of mini-batches"""
update_epochs: int = 4
"""the K epochs to update the policy"""
gamma: float = 0.99
"""the discount factor gamma"""
gae_lambda: float = 0.95
"""the lambda for the general advantage estimation"""
clip_coef: float = 0.2
"""the surrogate clipping coefficient"""
vf_coef: float = 0.5
"""coefficient of the value function"""
max_grad_norm: float = 0.5
"""the maximum norm for the gradient clipping"""
# to be filled in runtime
batch_size: int = 0
"""the batch size (computed in runtime)"""
minibatch_size: int = 0
"""the mini-batch size (computed in runtime)"""
num_iterations: int = 0
"""the number of iterations (computed in runtime)"""
args = Args()
Env#
import gymnasium as gym
# Vectorized environment that serially runs multiple environments.
envs = gym.vector.make(args.env_id, num_envs=args.num_envs, asynchronous=False)
envs
SyncVectorEnv(4)
Agent#
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions.categorical import Categorical
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
# Described in `Exact solutions to the nonlinear dynamics of learning in deep linear neural networks`
torch.nn.init.orthogonal_(layer.weight, std)
torch.nn.init.constant_(layer.bias, bias_const)
return layer
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
self.critic = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 1), std=1.0),
)
self.actor = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
)
def get_value(self, x):
return self.critic(x)
def get_action_and_value(self, x, action=None):
logits = self.actor(x)
probs = Categorical(logits=logits)
if action is None:
action = probs.sample()
return action, probs.log_prob(action), self.critic(x)
agent = Agent(envs=envs)
optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
Training loop#
# ALGO Logic: Storage setup
obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape)
actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape)
logprobs = torch.zeros((args.num_steps, args.num_envs))
rewards = torch.zeros((args.num_steps, args.num_envs))
dones = torch.zeros((args.num_steps, args.num_envs))
values = torch.zeros((args.num_steps, args.num_envs))
# start the game
next_obs, _ = envs.reset(seed=1) # (num_envs, observation_space)
next_obs = torch.Tensor(next_obs)
next_done = torch.zeros(args.num_envs)
args.batch_size = int(args.num_envs * args.num_steps)
args.minibatch_size = int(args.batch_size // args.num_minibatches)
args.num_iterations = args.total_timesteps // args.batch_size
for iteration in range(1, args.num_iterations + 1):
# collect data
for step in range(args.num_steps):
obs[step] = next_obs
dones[step] = next_done
# ALGO LOGIC: action logic
with torch.no_grad():
action, logprob, value = agent.get_action_and_value(next_obs)
values[step] = value.flatten() # (num_envs, 1)
actions[step] = action # (num_envs)
logprobs[step] = logprob # (num_envs)
# execute the game
next_obs, reward, terminations, truncations, infos = envs.step(action.numpy())
next_done = np.logical_or(terminations, truncations)
next_obs, next_done = torch.Tensor(next_obs), torch.Tensor(next_done)
rewards[step] = torch.tensor(reward).view(-1)
# compute advantages and rewards-to-go
with torch.no_grad():
next_value = agent.get_value(next_obs).reshape(1, -1)
advantages = torch.zeros_like(rewards)
lastgaelam = 0
for t in reversed(range(args.num_steps)):
if t == args.num_steps - 1:
nextnonterminal = 1.0 - next_done
nextvalues = next_value
else:
nextnonterminal = 1.0 - dones[t + 1]
nextvalues = values[t + 1]
delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
returns = advantages + values
# flatten the batch
b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
b_logprobs = logprobs.reshape(-1)
b_advantages = advantages.reshape(-1)
b_returns = returns.reshape(-1)
b_values = values.reshape(-1)
# Optimizing the policy and value network
b_inds = np.arange(args.batch_size)
for epoch in range(args.update_epochs):
np.random.shuffle(b_inds)
for start in range(0, args.batch_size, args.minibatch_size):
end = start + args.minibatch_size
mb_inds = b_inds[start: end]
_, newlogprob, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])
logratio = newlogprob - b_logprobs[mb_inds]
ratio = logratio.exp()
with torch.no_grad():
# calculate approx_kl http://joschu.net/blog/kl-approx.html
approx_kl = ((ratio - 1) - logratio).mean()
mb_advantages = b_advantages[mb_inds]
mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
# Policy loss
pg_loss1 = -mb_advantages * ratio
pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()
# Value loss
newvalue = newvalue.view(-1)
v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
v_clipped = b_values[mb_inds] + torch.clamp(
newvalue - b_values[mb_inds],
-args.clip_coef,
args.clip_coef)
v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
v_loss = 0.5 * v_loss_max.mean()
loss = pg_loss + v_loss * args.vf_coef
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
optimizer.step()
if epoch == args.update_epochs - 1 and iteration % 50 == 0:
print(iteration, loss.item())
envs.close()
50 33.084800720214844
50 37.232730865478516
50 34.39324951171875
50 33.84747314453125
100 23.348072052001953
100 22.117525100708008
100 23.936569213867188
100 25.712512969970703
150 9.753089904785156
150 9.89642333984375
150 11.062821388244629
150 10.868123054504395
200 18.555591583251953
200 29.088899612426758
200 25.934303283691406
200 32.978919982910156
250 9.040190696716309
250 8.059968948364258
250 6.952812194824219
250 6.297258377075195
300 2.508791446685791
300 3.2499616146087646
300 3.3858799934387207
300 3.5988214015960693
350 8.21420955657959
350 10.674125671386719
350 8.540313720703125
350 7.153816223144531