
Q-learning#
Note
Recall that Sarsa can only estimate the action values of a given policy, and it must be combined with a policy improvement step to find optimal policies.
By contrast, Q-learning can directly estimate optimal action values and find
optimal policies.
The Q-Learning algorithm#
Step 1: We initialize the Q-table

Step 2: Choose an action using the epsilon-greedy strategy
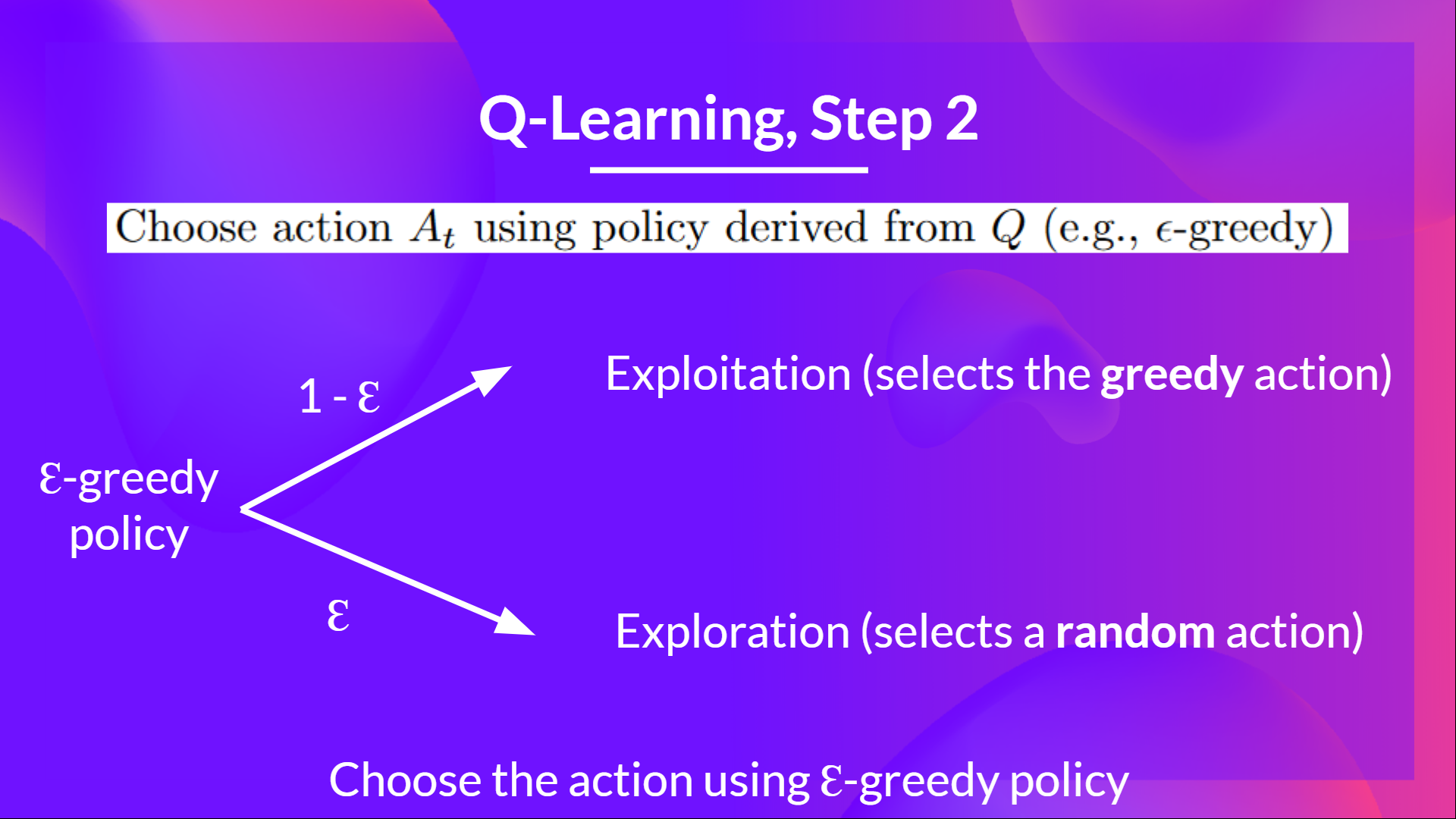
The epsilon-greedy strategy is a policy that handles the exploration/exploitation trade-off. The idea is that:
With probability \(1-\epsilon\) : we do exploitation (our agent selects the action with the highest state-action pair value).
With probability \(\epsilon\) : we do exploration (trying random action).
At the beginning of the training, the probability of doing exploration will be huge since \(\epsilon\) is very high, so most of the time, we’ll explore. But as the training goes on, and consequently our Q-table gets better and better in its estimations, we progressively reduce the epsilon value since we will need less and less exploration and more exploitation.
Step 3: Perform action \(A_{t}\), get reward \(R_{t+1}\) and next state \(S_{t+1}\)
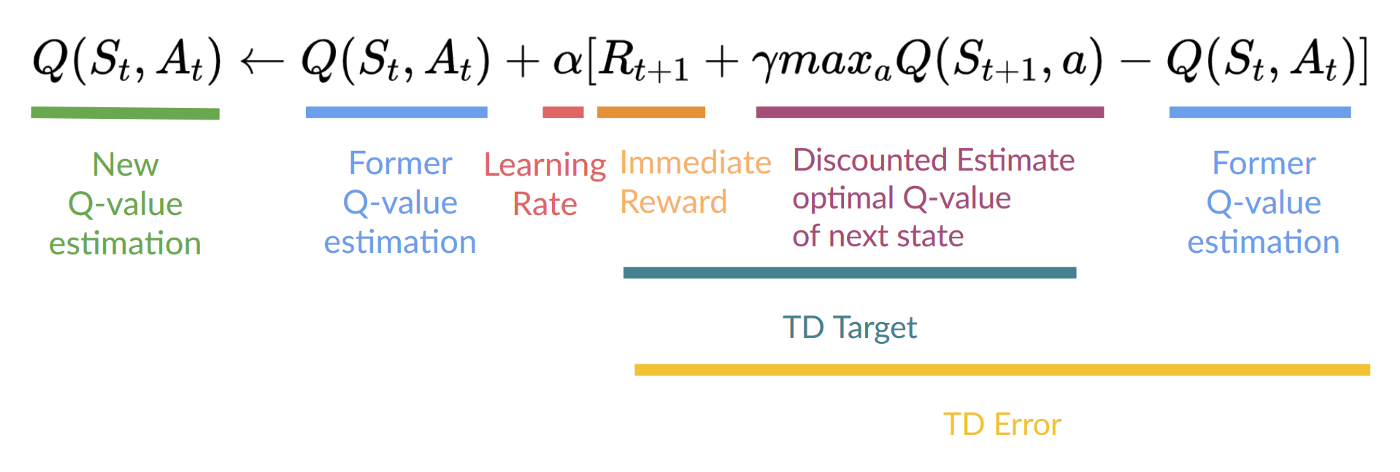
Step 4: Update \(Q(S_t, A_t)\)
Remember that in TD Learning, we update our value function after one step of the interaction.
In Q-learning, to produce our TD target, we used the immediate reward \(R_{t+1}\) plus the discounted value of the next state, computed by finding the action that maximizes the current Q-function at the next state.
Tip
Q-learning is a stochastic approximation algorithm for solving the Bellman optimality equation expressed in terms of action values:
Off-policy vs On-policy#
Note
What makes Q-learning special compared to the other TD algorithms is that Q-learning is off-policy while the others are on-policy.
Two policies exist in any reinforcement learning task: a behavior policy and a target policy. The behavior policy is the one used to generate experience samples. The target policy is the one that is constantly updated to converge to an optimal policy. When the behavior policy is the same as the target policy, such a learning process is called on-policy. Otherwise, when they are different, the learning process is called off-policy.
Sarsa is on-policy. The samples required by Sarsa in every iteration include \((S_t, A_t, R_{t+1}, S_{t+1}, A_{t+1})\). How these samples are generated is illustrated below:
\[S_{t},A_{t}\overset{\text{enviroment}}{\longrightarrow}R_{t+1},S_{t+1}\overset{\pi}{\longrightarrow}A_{t+1}\]\(A_{t+1}\) is dependent on the target policy \(\pi\).
Q-learning is off-policy. The samples required by Q-learning in every iteration is \((S_t, A_t, R_{t+1}, S_{t+1})\). How these samples are generated is illustrated below:
\[S_{t},A_{t}\overset{\text{enviroment}}{\longrightarrow}R_{t+1},S_{t+1}\]the estimation of the optimal action value of \((S_t, A_t)\) does not involve \(\pi\) and we can use any policy to generate samples.