
Policy Gradient#
Note
Since the beginning of the course, we have only studied value-based methods, where we estimate a value function as an intermediate step towards finding an optimal policy. Finding an optimal value function leads to having an optimal policy:
With policy-based methods, we want to optimize the policy directly without having an intermediate step of learning a value function.
The policy-gradient methods#
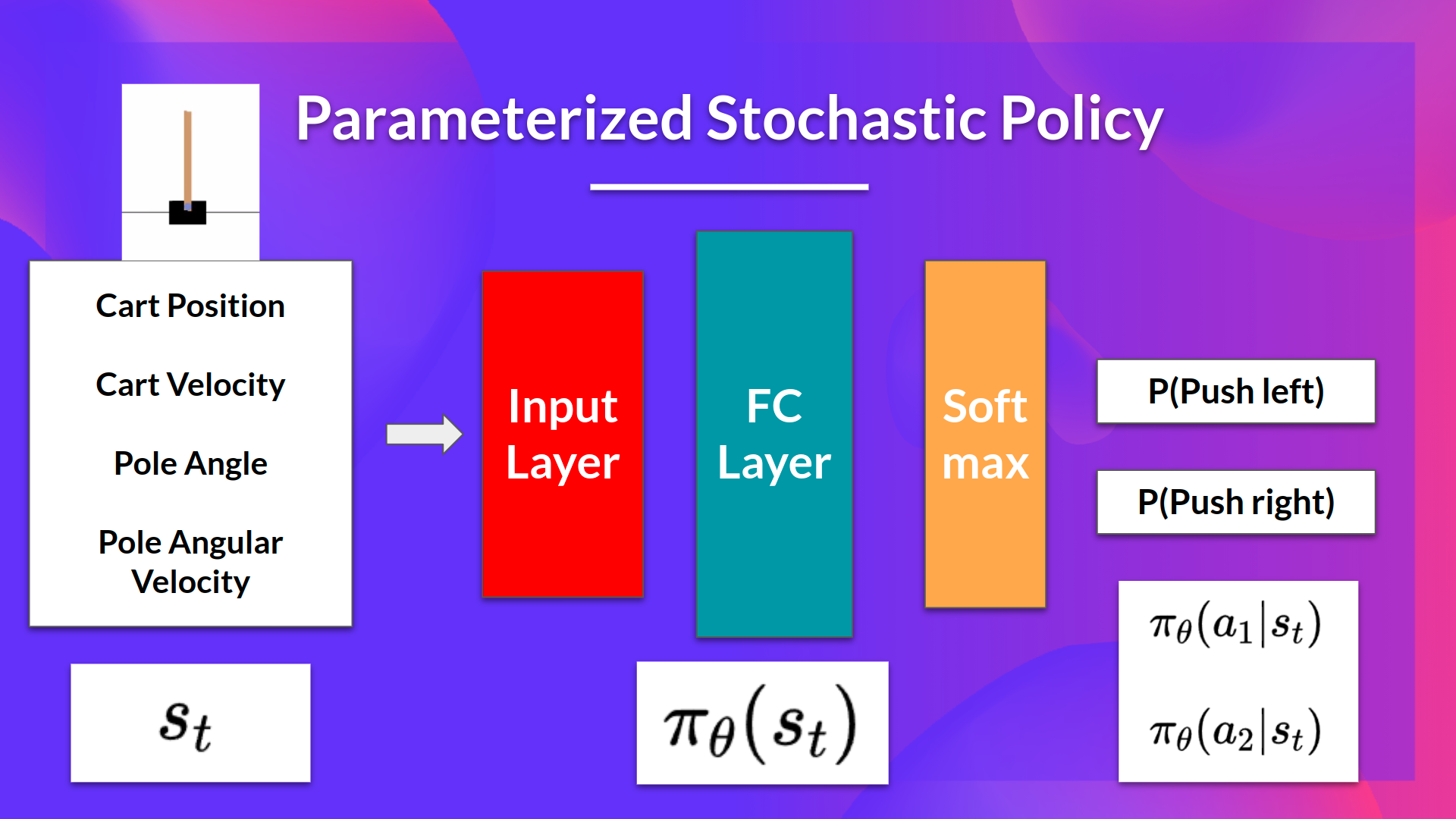
In policy-based methods, we directly learn to approximate \(\pi^{\ast}\).
The idea is to parameterize the policy. For instance, using a neural network \(\pi_{\theta}\), this policy will output a probability distribution over actions (stochastic policy).
Our objective then is to maximize the performance of the parameterized policy using gradient ascent. To do that, we define an objective function \(J(\theta)\), that is, the expected cumulative reward, and we want to find the value \(\theta\) that maximizes this objective function.
Advantages and disadvantages of policy-gradient methods#
Policy-gradient methods have multiple advantages over value-based methods:
Policy-gradient methods can learn a stochastic policy while value functions can’t.
Policy-gradient methods are more effective in high-dimensional action spaces and continuous actions spaces.
Policy-gradient methods have better convergence properties.
Naturally, policy-gradient methods also have some disadvantages:
Frequently, policy-gradient methods converges to a local maximum instead of a global optimum.
Policy-gradient goes slower, step by step: it can take longer to train.
Policy-gradient can have high variance.
The Policy Gradient Theorem#
The objective function outputs the expected cumulative reward:
It can be formulated as:

Policy-gradient is an optimization problem: we want to find the values of \(\theta\) that maximize our objective function \(J(\theta)\), so we can use gradient-ascent:
However, there are two problems with computing the derivative of \(J(\theta)\):
We can’t calculate the true gradient of the objective function since it requires calculating the probability of each possible trajectory, which is computationally super expensive. So we want to calculate a gradient estimation with a sample-based estimate.
To differentiate this objective function, we need to differentiate the state distribution, this is attached to the environment.
Fortunately we’re going to use a solution called the Policy Gradient Theorem that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.

Proof. We have:
The Reinforce algorithm (Monte Carlo Reinforce)#
In a loop:
Use the policy \(\pi_{\theta}\) to collect some episodes
Use these episodes to estimate the gradient.
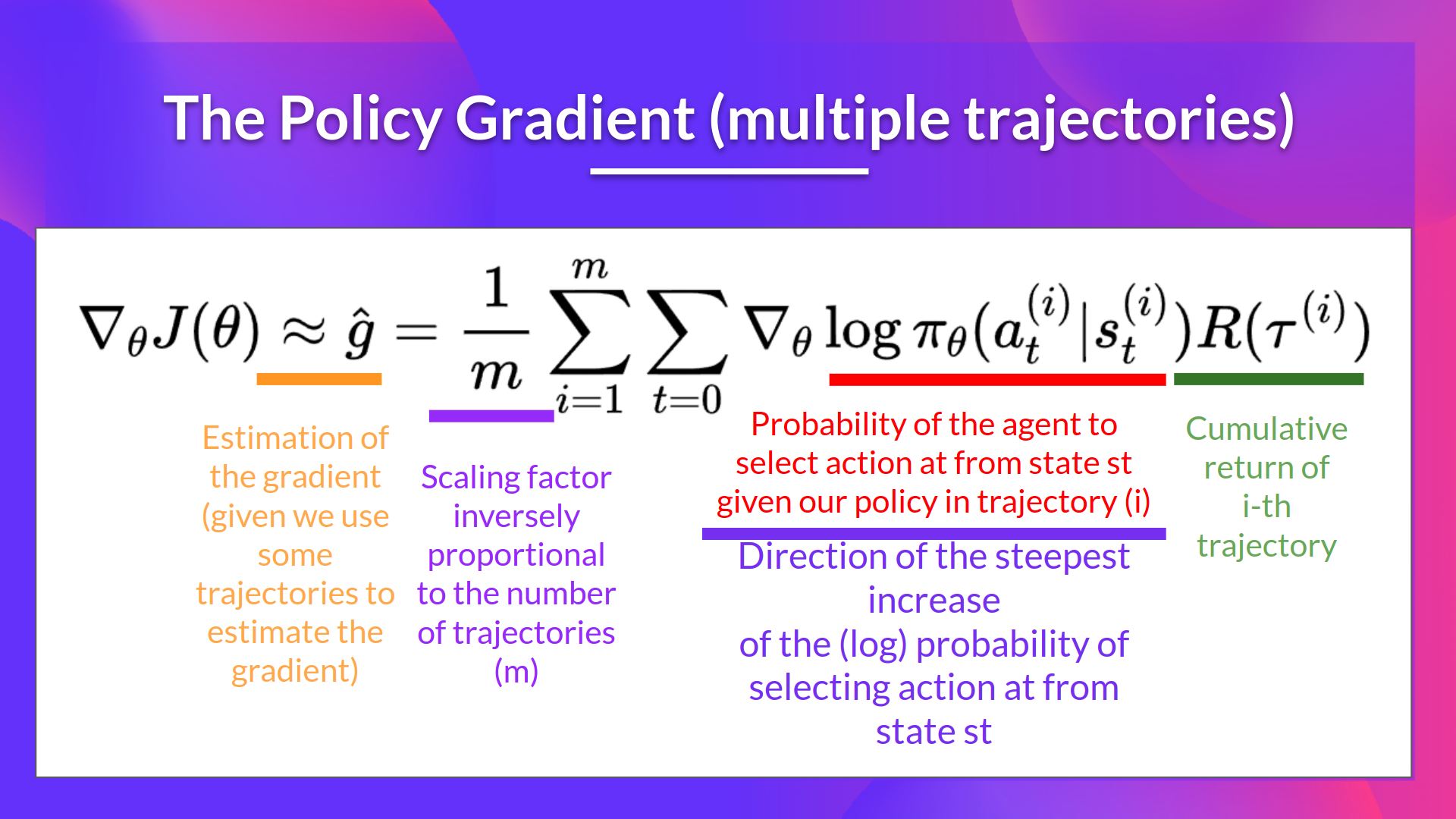
We can interpret this update as follows: \(-\nabla_{\theta}\log\pi_{\theta}(a_{t}|s_{t})\) is the direction of steepest increase of the (log) probability of selecting action at from state \(s_{t}\). This tells us:
If the return \(R(\tau)\) is high, it will push up the probabilities of the (state, action) combinations.
Otherwise, it will push down the probabilities of the (state, action) combinations.
Don’t Let the Past Distract You#
Examine our most recent expression for the policy gradient:
Taking a step with this gradient pushes up the log-probabilities of each action in proportion to \(R(\tau)\), the sum of all rewards ever obtained. But this doesn’t make much sense.
Agents should really only reinforce actions on the basis of their consequences. Rewards obtained before taking an action have no bearing on how good that action was: only rewards that come after.
It turns out that this intuition shows up in the math, and we can show that the policy gradient can also be expressed by:
In this form, actions are only reinforced based on rewards obtained after they are taken. We’ll call this form the “reward-to-go policy gradient”, because the sum of rewards after a point in a trajectory,
is called the reward-to-go from that point, and this policy gradient expression depends on the reward-to-go from state-action pairs.
Tip
A key problem with policy gradients is how many sample trajectories are needed to get a low-variance sample estimate for them. The formula we started with included terms for reinforcing actions proportional to past rewards, all of which had zero mean, but nonzero variance: as a result, they would just add noise to sample estimates of the policy gradient. By removing them, we reduce the number of sample trajectories needed.
A proof of this claim is in Appendix A.
Pytorch example#
Env#
import gym
env = gym.make('CartPole-v1')
env.reset(seed=1)
env.observation_space.shape[0], env.action_space.n
(4, 2)
Policy network#
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Policy(nn.Module):
"""MLP"""
def __init__(self):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
self.dropout = nn.Dropout(p=0.6)
self.affine2 = nn.Linear(128, 2)
self.saved_log_probs = []
self.rewards = []
def forward(self, x):
x = self.affine1(x)
x = self.dropout(x)
x = F.relu(x)
action_scores = self.affine2(x)
return F.softmax(action_scores, dim=1)
policy = Policy()
optimizer = optim.Adam(policy.parameters(), lr=1e-2)
*self.saved_log_probs saves \(\left[\pi_{\theta}(a_{0}|s_{0}), \pi_{\theta}(a_{1}|s_{1}),\dots,\pi_{\theta}(a_{T}|s_{T})\right]\)
*self.rewards saves \(\left[r_{0},r_{1},\dots,r_{T}\right]\)
One episode#
import numpy as np
from torch.distributions import Categorical
def select_action(state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = policy(state)
m = Categorical(probs)
action = m.sample()
policy.saved_log_probs.append(m.log_prob(action))
return action.item()
gamma = 0.99
def finish_episode():
R = 0
eps = np.finfo(np.float32).eps.item()
policy_loss = []
returns = deque()
for r in policy.rewards[::-1]:
R = r + gamma * R
returns.appendleft(R)
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + eps)
for log_prob, R in zip(policy.saved_log_probs, returns):
policy_loss.append(-log_prob * R)
optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
optimizer.step()
del policy.rewards[:]
del policy.saved_log_probs[:]
returns = \(\left[R_{0}, R_{1}, \dots, R_{T}\right]\) where \(R_{t} = r_{t} + \gamma r_{t+1} + \gamma^{2}r_{t+2} + \dots\)
policy_loss = \(\sum_{i=0}^{T}-\log\pi_{\theta}(a_{t}|s_{t})R_{t}\)
Main loop#
from itertools import count
from collections import deque
def main():
running_reward = 10
for i_episode in count(1):
state, _ = env.reset()
ep_reward = 0
for t in range(1, 10000): # Don't infinite loop while learning
action = select_action(state)
state, reward, done, _, _ = env.step(action)
policy.rewards.append(reward)
ep_reward += reward
if done:
break
running_reward = 0.05 * ep_reward + (1 - 0.05) * running_reward
finish_episode()
if i_episode % 10 == 0:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(
i_episode, ep_reward, running_reward))
if running_reward > env.spec.reward_threshold:
print("Solved! Running reward is now {} and "
"the last episode runs to {} time steps!".format(running_reward, t))
break
main()
/Users/xiayunhui/miniconda3/lib/python3.12/site-packages/gym/utils/passive_env_checker.py:233: DeprecationWarning: `np.bool8` is a deprecated alias for `np.bool_`. (Deprecated NumPy 1.24)
if not isinstance(terminated, (bool, np.bool8)):
Episode 10 Last reward: 13.00 Average reward: 14.12
Episode 20 Last reward: 15.00 Average reward: 15.92
Episode 30 Last reward: 19.00 Average reward: 23.73
Episode 40 Last reward: 77.00 Average reward: 31.66
Episode 50 Last reward: 36.00 Average reward: 37.63
Episode 60 Last reward: 139.00 Average reward: 53.00
Episode 70 Last reward: 65.00 Average reward: 57.67
Episode 80 Last reward: 124.00 Average reward: 64.87
Episode 90 Last reward: 68.00 Average reward: 89.74
Episode 100 Last reward: 67.00 Average reward: 92.94
Episode 110 Last reward: 58.00 Average reward: 85.80
Episode 120 Last reward: 64.00 Average reward: 89.75
Episode 130 Last reward: 97.00 Average reward: 101.48
Episode 140 Last reward: 398.00 Average reward: 169.40
Episode 150 Last reward: 302.00 Average reward: 216.14
Episode 160 Last reward: 302.00 Average reward: 401.73
Episode 170 Last reward: 121.00 Average reward: 300.78
Episode 180 Last reward: 643.00 Average reward: 309.24
Episode 190 Last reward: 223.00 Average reward: 326.53
Episode 200 Last reward: 235.00 Average reward: 298.82
Episode 210 Last reward: 348.00 Average reward: 270.26
Solved! Running reward is now 499.12600625382424 and the last episode runs to 1580 time steps!
Appendix A: Proof for Don’t Let the Past Distract You#
The proof of this claim depends on the EGLP lemma: Suppose that \(P_{\theta}\) is a parameterized probability distribution over a random variable, \(x\). Then:
Proof. Recall that all probability distributions are normalized:
Take the gradient of both sides of the normalization condition:
Use the log derivative trick to get:
Expand out \(R(\tau)\) in the expression for the simplest policy gradient to obtain:
and consider the term
We will show that for the case of \(t'<t\) (the reward comes before the action being reinforced), this term is zero.
At this point, we will only worry about the innermost expectation,
We now have to make a distinction between two cases: If \(t'<t\), the case where the reward happened before the action, then the conditional probabilities for actions at \(a_{t}\) come from the policy:
the innermost expectation can be broken down farther into
The EGLP lemma says that
allowing us to conclude that for \(t'<t, \mathbb{E}_{\tau\sim\pi_{\theta}}[f(t,t')] = 0\).
Appendix B: Baselines in Policy Gradients#
An immediate consequence of the EGLP lemma is that for any function \(b\) which only depends on state,
This allows us to add or subtract any number of terms like this from our expression for the policy gradient, without changing it in expectation:
Any function \(b\) used in this way is called a baseline.
The most common choice of baseline is the on-policy value function \(V^{\pi}(s_t)\). Recall that this is the average return an agent gets if it starts in state \(s_t\) and then acts according to policy \(\pi\) for the rest of its life. Empirically, the choice \(b(s_t) = V^{\pi}(s_t)\) has the desirable effect of reducing variance in the sample estimate for the policy gradient. This results in faster and more stable policy learning.
Note
In practice, \(V^{\pi}(s_t)\) cannot be computed exactly, so it has to be approximated. This is usually done with a neural network, \(V_{\phi}(s_t)\), which is updated concurrently with the policy (so that the value network always approximates the value function of the most recent policy).
The simplest method for learning \(V_{\phi}\), used in most implementations of policy optimization algorithms, is to minimize a mean-squared-error objective:
where \(\pi_k\) is the policy at epoch \(k\). This is done with one or more steps of gradient descent, starting from the previous value parameters \(\phi_{k-1}\).
Appendix C: Other Forms of the Policy Gradient#
What we have seen so far is that the policy gradient has the general form
where \(\Phi_t\) could be any of
or
or
All of these choices lead to the same expected value for the policy gradient, despite having different variances. It turns out that there are two more valid choices of weights \(\Phi_t\) which are important to know.
On-Policy Action-Value Function. The choice
\[\Phi_t = Q^{\pi_{\theta}}(s_t, a_t)\]is also valid. See this page for an (optional) proof of this claim.
The Advantage Function defined by \(A^{\pi}(s_t,a_t) = Q^{\pi}(s_t,a_t) - V^{\pi}(s_t)\), describes how much better or worse it is than other actions on average (relative to the current policy). This choice,
\[\Phi_t = A^{\pi_{\theta}}(s_t, a_t)\]is also valid.