
Mean Shift#
Note
Mean shift 是 shift to the mean 的意思。
思路#
一般来说,聚类中心周围的点都是很密集的,越靠近聚类中心点越密集。
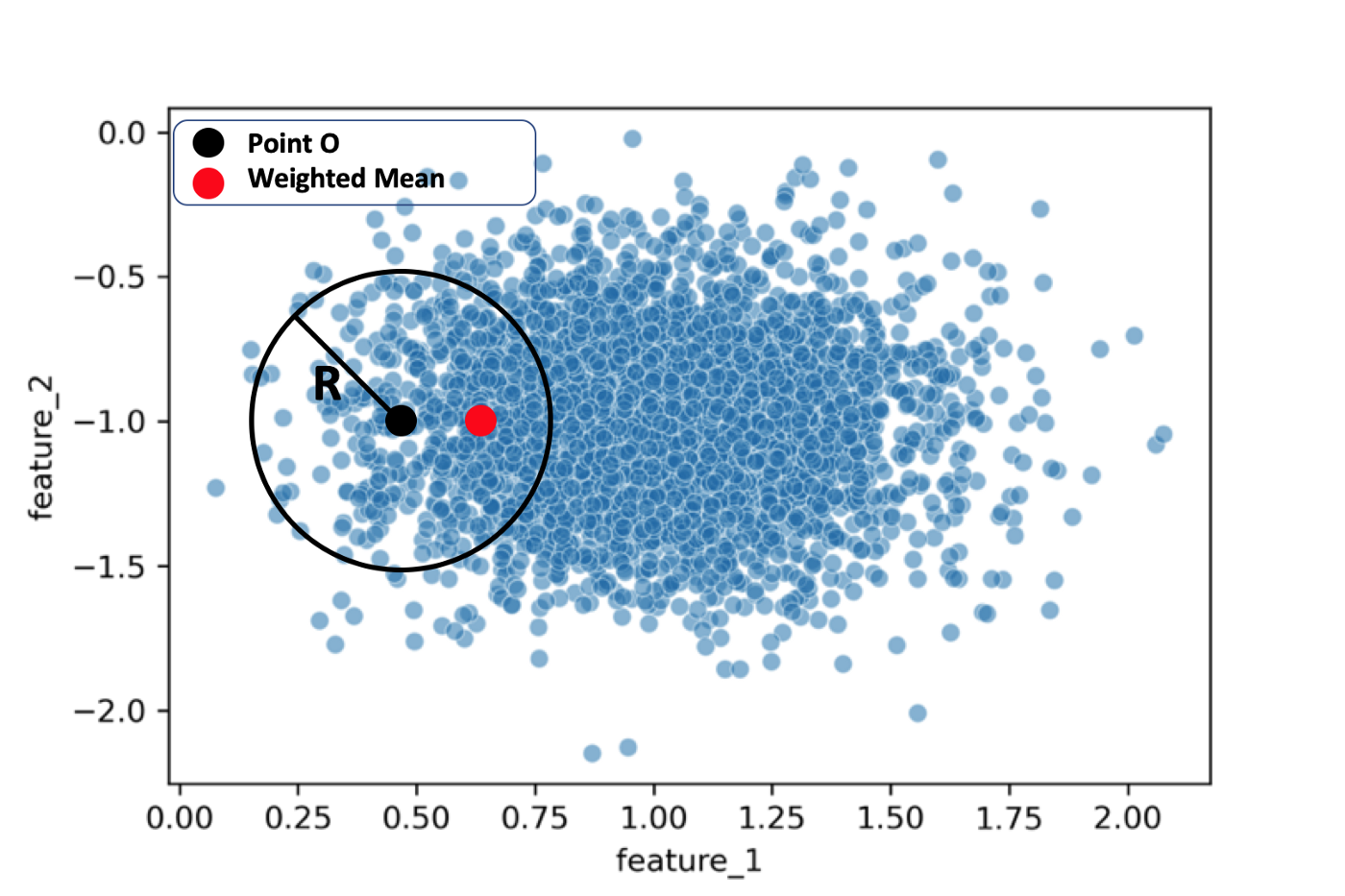
我们如何利用这个特性让点逐渐漂移到聚类中心从而完成聚类呢?我们只要让点往密集的地方漂移就好了!可以以这个点为中心画一个圈作为邻域,计算邻域内所有点的均值,均值会偏向点密度更高的地方,如下图所示:
就这样,每个点一步接一步地漂向聚类中心周围,漂向同一个地方的点被认为是在同一个聚类:
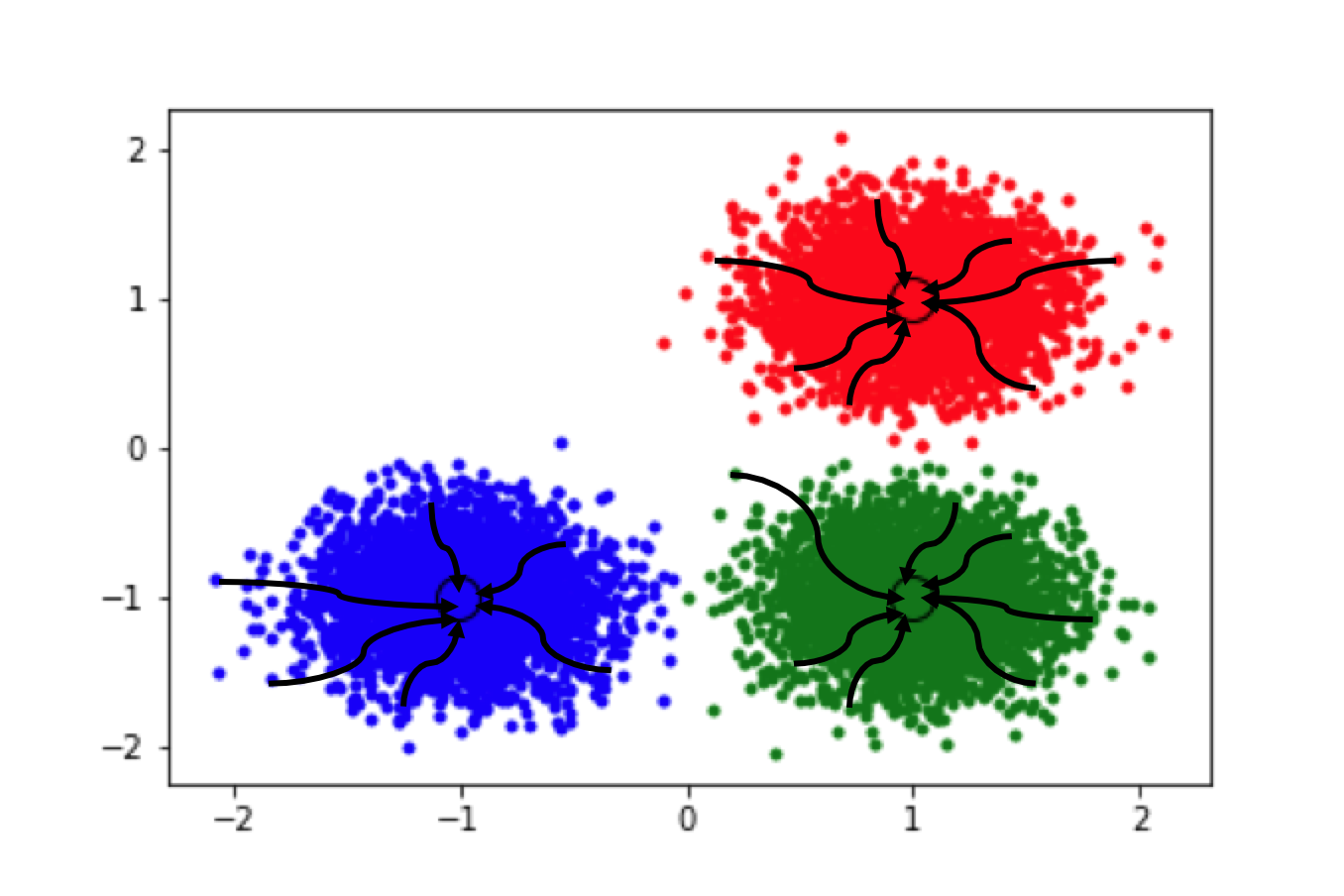
Mean shift 唯一的参数就是圈的直径的大小,即 bandwidth,它越大簇越少,它越小簇越多。
使用方法#
import numpy as np
# (n_samples, n_features)
X = np.array([[1, 1], [2, 1], [1, 0],
[4, 7], [3, 5], [3, 6]])
from sklearn.cluster import MeanShift
# 需指定 bandwidth
clustering = MeanShift(bandwidth=2).fit(X)
clustering.labels_
array([1, 1, 1, 0, 0, 0])
clustering.predict([[0, 0], [5, 5]])
array([1, 0])