
KNN#
KNN(K-Nearest Neighbors) is a non-parametric classification method used for classification and regression.
The principle behind nearest neighbor methods is to find a predefined number of training samples closest in distance to the new point, and predict the label from these.
In KNN classification, the output is a class membership. An object is classified by a vote of its neighbors.
In KNN regression, the output is the average of the values of \(k\) nearest neighbors.
The optimal choice of the value \(k\) is highly data-dependent: in general, a larger \(k\) suppresses the effects of noise, but makes the classification boundaries less distinct.
Examples#
"""KNN classification"""
from sklearn.neighbors import KNeighborsClassifier
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
clf = KNeighborsClassifier(n_neighbors=3,
algorithm="kd_tree")
clf.fit(X, y)
clf.predict([[1.1]]), clf.predict_proba([[0.9]])
(array([0]), array([[0.66666667, 0.33333333]]))
"""KNN regression"""
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor(n_neighbors=2,
weights="uniform")
reg.fit(X, y)
reg.predict([[1.5]])
array([0.5])
KDTree#
A k-d tree (short for k-dimensional tree) is a space-partitioning data structure for organizing points in a k-dimensional space.
It’s useful in searching nearest neighors in KNN.
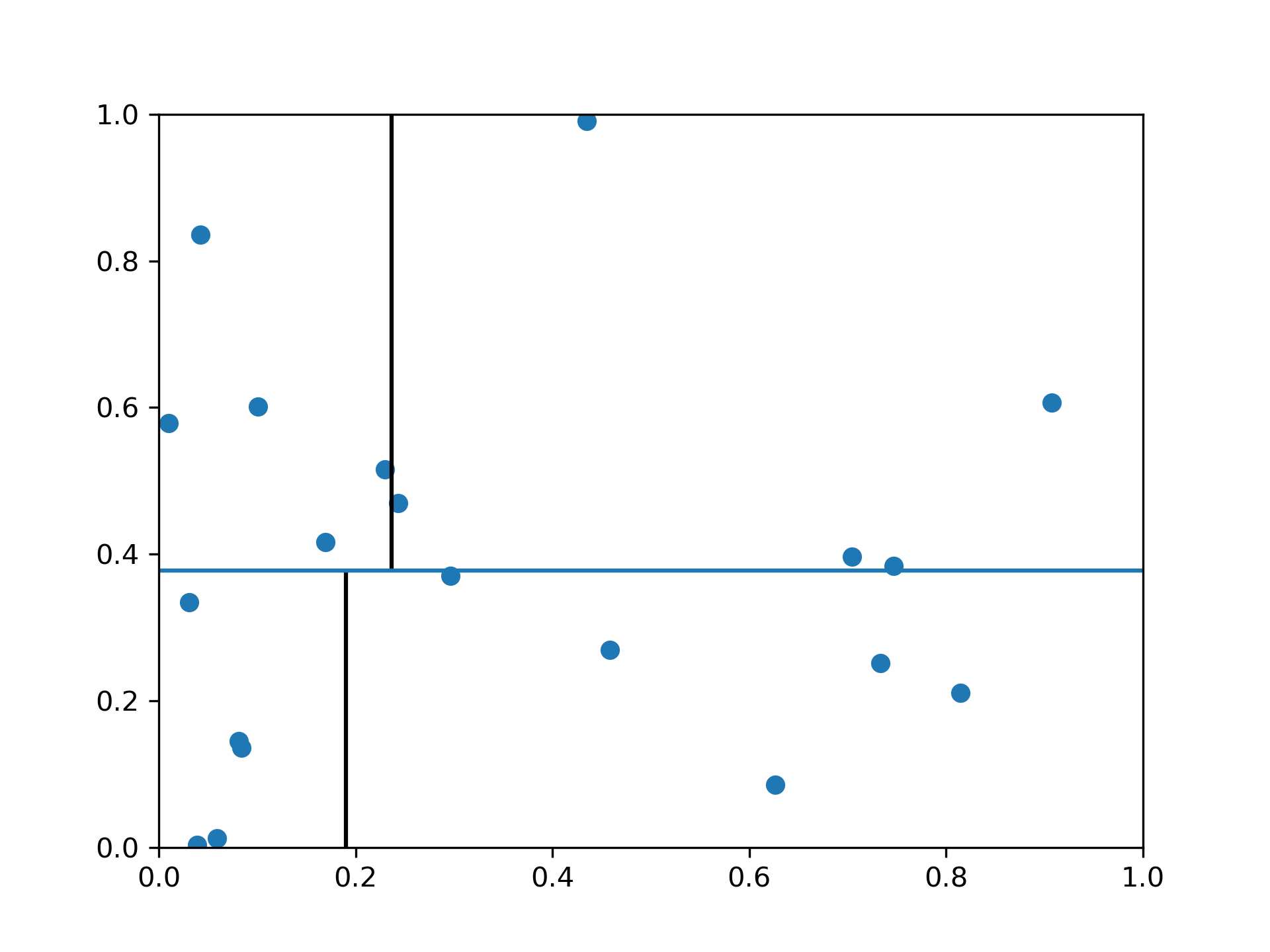
As the above fiture, k-d tree first split dataset through y-axis into two equivalent subsets, then split each subset through x-axis, and so on.
When searching for nearest neighors, k-d tree first locate the new instance’s leaf, then only search in and near that leaf.