
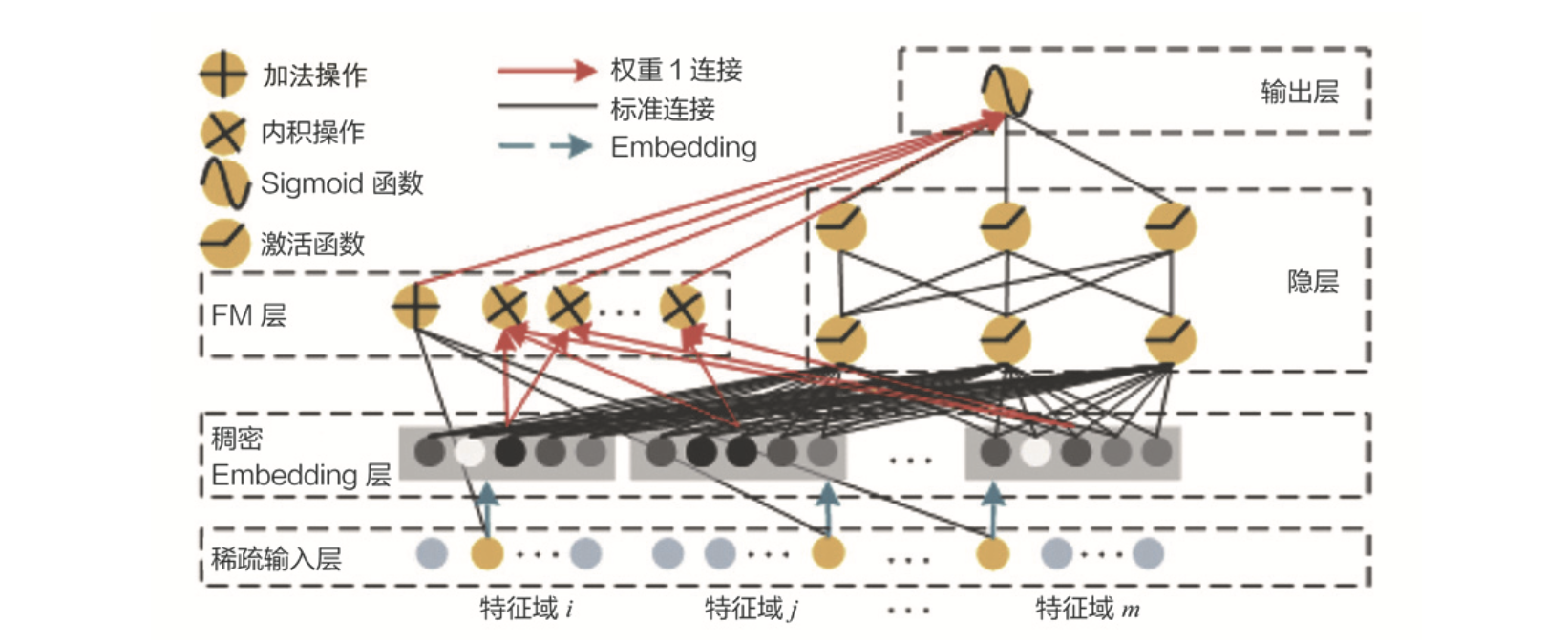
DeepFM
Contents
DeepFM#
Note
Emebedding+MLP,Wide&Deep,NeuralCF都没有对特征交叉进行特别的处理,只能硬train,这样抓取交叉特征的效率不高。
DeepFM使用因子分解机(Factorization Machine,FM)专门用于特征交叉。
FM#
因子分解机的结构:
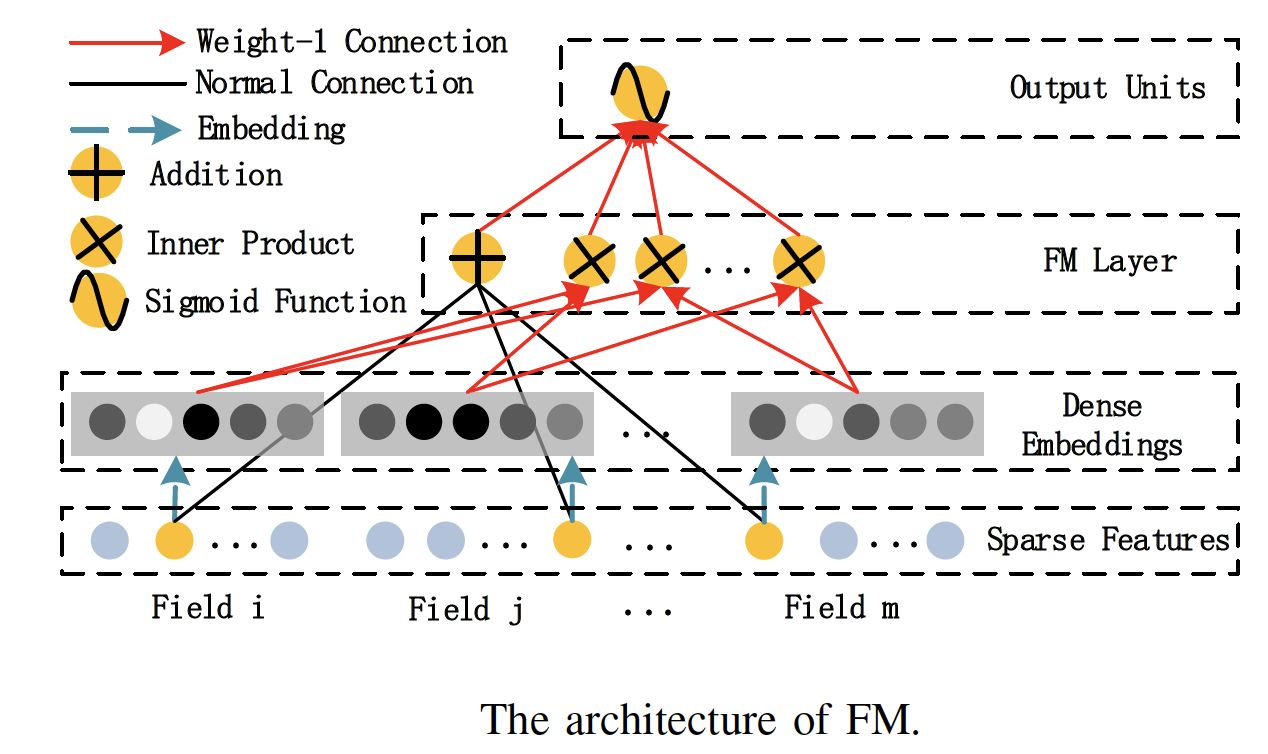
在线性模型:
$$y = b + \sum_{i=1}^{n}\omega_{i}x_{i}$$
的基础上引入二阶交叉项,得到二阶多项式模型:
$$y = b + \sum_{i=1}^{n}\omega_{i}x_{i} + \sum_{i=1}^{n}\sum_{j=i+1}^{n}\omega_{ij}x_{i}x_{j}$$
若直接使用二阶多项式建模,组合部分有$\frac{n(n-1)}{2}$个参数,很难训练。
因此我们采用类似矩阵分解的技术,$W \approx \hat{W} = VV^{T}$,其中$V \in \mathbb{R}^{n\times{k}}$,k一般较小。
$$y = b + \sum_{i=1}^{n}\omega_{i}x_{i} + \sum_{i=1}^{n}\sum_{j=i+1}^{n}\left \langle{v_{i},v_{j}} \right \rangle x_{i}x_{j}$$
二阶参数只有 $nk$ 个,较易训练,这就是FM。
数据预处理#
import tensorflow as tf
from tensorflow import keras
import rec
# 读取movielens数据集
train_dataset, test_dataset = rec.load_movielens()
定义inputs#
# define input for keras model
inputs = {
'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),
'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),
'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),
'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),
'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),
'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),
'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),
'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),
'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),
'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),
'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),
}
定义特征#
# movie id embedding feature
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
# user id embedding feature
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
# 电影的类别
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War',
'Comedy', 'Western', 'Documentary', 'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
# 只使用userGenre1和movieGenre1
# user genre embedding feature
user_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="userGenre1",
vocabulary_list=genre_vocab)
user_genre_emb_col = tf.feature_column.embedding_column(user_genre_col, 10)
# item genre embedding feature
item_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="movieGenre1",
vocabulary_list=genre_vocab)
item_genre_emb_col = tf.feature_column.embedding_column(item_genre_col, 10)
tf.feature_column.indicator_column: 包装任何categorical_column,然后作为模型的input_layer的输入。
# movid id indicator columns
movie_ind_col = tf.feature_column.indicator_column(movie_col)
# user id indicator columns
user_ind_col = tf.feature_column.indicator_column(user_col)
# user genre indicator columns
user_genre_ind_col = tf.feature_column.indicator_column(user_genre_col)
# item genre indicator columns
item_genre_ind_col = tf.feature_column.indicator_column(item_genre_col)
"""
Deep部分的特征
"""
deep_feature_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev'),
movie_emb_col,
user_emb_col]
模型#
"""
1阶部分
"""
# fm first-order term columns: without embedding and concatenate to the output layer directly
fm_first_order_columns = [movie_ind_col, user_ind_col, user_genre_ind_col, item_genre_ind_col]
# The first-order term in the FM layer
fm_first_order_layer = tf.keras.layers.DenseFeatures(fm_first_order_columns)(inputs)
"""
cross部分
"""
# from inputs to embedding
item_emb_layer = tf.keras.layers.DenseFeatures([movie_emb_col])(inputs)
user_emb_layer = tf.keras.layers.DenseFeatures([user_emb_col])(inputs)
item_genre_emb_layer = tf.keras.layers.DenseFeatures([item_genre_emb_col])(inputs)
user_genre_emb_layer = tf.keras.layers.DenseFeatures([user_genre_emb_col])(inputs)
# cross different categorical feature embeddings
product_layer_item_user = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_emb_layer])
product_layer_item_genre_user_genre = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_genre_emb_layer])
product_layer_item_genre_user = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_emb_layer])
product_layer_user_genre_item = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_genre_emb_layer])
"""
Deep部分
"""
deep = tf.keras.layers.DenseFeatures(deep_feature_columns)(inputs)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)
"""
合并FM部分和Deep部分
"""
concat_layer = tf.keras.layers.concatenate([fm_first_order_layer,
product_layer_item_user,
product_layer_item_genre_user_genre,
product_layer_item_genre_user,
product_layer_user_genre_item,
deep], axis=1)
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(concat_layer)
# 最终的模型
model = tf.keras.Model(inputs, output_layer)
训练#
# compile the model, set loss function, optimizer and evaluation metrics
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', tf.keras.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])
# train the model
model.fit(train_dataset, epochs=5)
Epoch 1/5
/Users/facer/opt/anaconda3/lib/python3.8/site-packages/keras/engine/functional.py:582: UserWarning: Input dict contained keys ['rating', 'timestamp', 'movieGenre2', 'movieGenre3', 'userRatedMovie1', 'userRatedMovie2', 'userRatedMovie3', 'userRatedMovie4', 'userRatedMovie5', 'userAvgReleaseYear', 'userReleaseYearStddev', 'userGenre2', 'userGenre3', 'userGenre4', 'userGenre5'] which did not match any model input. They will be ignored by the model.
warnings.warn(
7403/7403 [==============================] - 36s 5ms/step - loss: 0.6396 - accuracy: 0.6518 - auc: 0.6965 - auc_1: 0.7264
Epoch 2/5
7403/7403 [==============================] - 33s 4ms/step - loss: 0.5625 - accuracy: 0.7105 - auc: 0.7763 - auc_1: 0.8055
Epoch 3/5
7403/7403 [==============================] - 36s 5ms/step - loss: 0.4983 - accuracy: 0.7578 - auc: 0.8341 - auc_1: 0.8596
Epoch 4/5
7403/7403 [==============================] - 32s 4ms/step - loss: 0.4249 - accuracy: 0.8037 - auc: 0.8843 - auc_1: 0.9050
Epoch 5/5
7403/7403 [==============================] - 32s 4ms/step - loss: 0.3539 - accuracy: 0.8438 - auc: 0.9217 - auc_1: 0.9372
<keras.callbacks.History at 0x7fe21a5cf640>