
Embedding + MLP
Contents
Embedding + MLP#
Note
Embedding + MLP是最经典的深度学习推荐模型结构,也是后续诸多模型的基础。
结构#
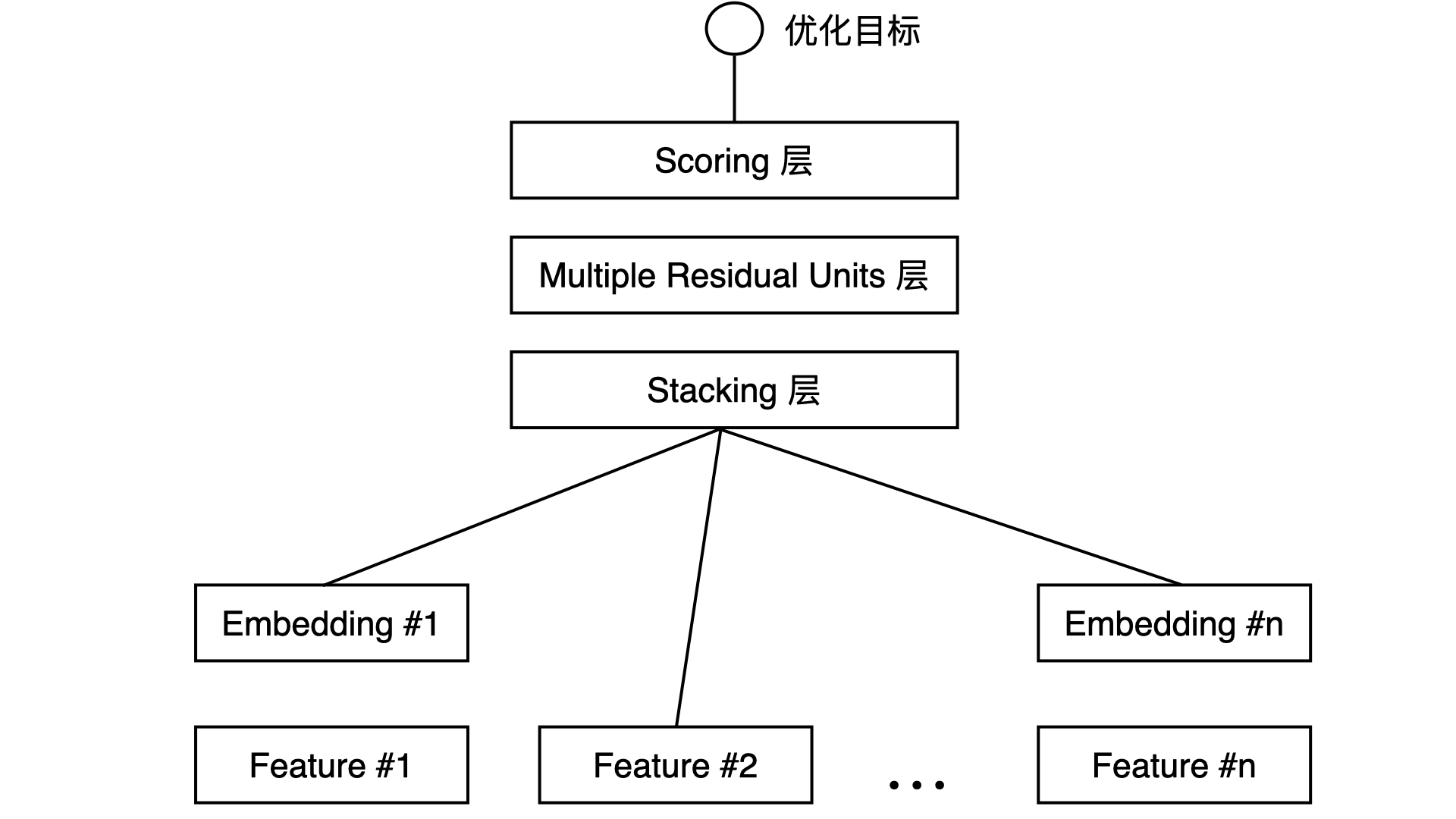
Feature层:类别型特征向上连接到Embedding层,而数值型特征则直接连接到Stacking层。
Embedding层:将类别型特征转化为稠密向量。
Stacking层:堆叠层,即将各个向量拼接(concatenate)在一起。
MLP层:多层神经网络,这里使用了残差(residual)结构,我们使用普通的MLP也可以。
Scoring层:输出层,若是CTR预估则使用Sigmoid激活函数。
数据预处理#
import tensorflow as tf
from tensorflow import keras
import rec
# 读取movielens数据集
train_dataset, test_dataset = rec.load_movielens()
rec.get_movielens_df()
| movieId | userId | rating | timestamp | label | releaseYear | movieGenre1 | movieGenre2 | movieGenre3 | movieRatingCount | ... | userRatingCount | userAvgReleaseYear | userReleaseYearStddev | userAvgRating | userRatingStddev | userGenre1 | userGenre2 | userGenre3 | userGenre4 | userGenre5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 15555 | 3.0 | 900953740 | 0 | 1995 | Adventure | Animation | Children | 10759 | ... | 92 | 1992 | 8.98 | 3.86 | 0.74 | Drama | Comedy | Thriller | Action | Crime |
| 1 | 1 | 25912 | 3.5 | 1111631768 | 1 | 1995 | Adventure | Animation | Children | 10759 | ... | 21 | 1988 | 14.09 | 3.48 | 1.28 | Action | Comedy | Romance | Adventure | Thriller |
| 2 | 1 | 29912 | 3.0 | 866820360 | 0 | 1995 | Adventure | Animation | Children | 10759 | ... | 4 | 1995 | 0.50 | 3.00 | 0.00 | NaN | NaN | NaN | NaN | NaN |
| 3 | 10 | 17686 | 0.5 | 1195555011 | 0 | 1995 | Action | Adventure | Thriller | 6330 | ... | 35 | 1992 | 8.35 | 2.97 | 1.48 | Comedy | Drama | Adventure | Action | Thriller |
| 4 | 104 | 20158 | 4.0 | 1155357691 | 1 | 1996 | Comedy | NaN | NaN | 3954 | ... | 81 | 1991 | 8.70 | 3.60 | 0.72 | Thriller | Drama | Action | Crime | Adventure |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 88822 | 968 | 26865 | 3.0 | 854092232 | 0 | 1968 | Horror | Sci-Fi | Thriller | 1824 | ... | 94 | 1991 | 12.23 | 3.35 | 0.85 | Drama | Thriller | Comedy | Crime | Romance |
| 88823 | 968 | 8507 | 2.0 | 974709061 | 0 | 1968 | Horror | Sci-Fi | Thriller | 1824 | ... | 5 | 1994 | 0.89 | 2.00 | 1.00 | NaN | NaN | NaN | NaN | NaN |
| 88824 | 969 | 16689 | 5.0 | 857854044 | 1 | 1951 | Adventure | Comedy | Romance | 2380 | ... | 97 | 1992 | 9.95 | 3.53 | 0.82 | Drama | Comedy | Crime | Romance | Thriller |
| 88825 | 969 | 26460 | 2.0 | 1250279576 | 0 | 1951 | Adventure | Comedy | Romance | 2380 | ... | 55 | 1990 | 11.78 | 2.73 | 1.42 | Thriller | Crime | Drama | Comedy | Sci-Fi |
| 88826 | 970 | 3033 | 2.0 | 1272394603 | 0 | 1953 | Adventure | Comedy | Crime | 98 | ... | 100 | 1985 | 17.64 | 3.67 | 0.89 | Drama | Romance | Comedy | Thriller | Crime |
88827 rows × 27 columns
处理类别型特征#
tf.feature_column.categorical_column_with_vocabulary_list: 指定vocab,将值转化成one-hot
tf.feature_column.embedding_column: one-hot转化为embedding
# 电影的类别
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War',
'Comedy', 'Western', 'Documentary', 'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
# 类别列
GENRE_FEATURES = {
'userGenre1': genre_vocab,
'userGenre2': genre_vocab,
'userGenre3': genre_vocab,
'userGenre4': genre_vocab,
'userGenre5': genre_vocab,
'movieGenre1': genre_vocab,
'movieGenre2': genre_vocab,
'movieGenre3': genre_vocab
}
categorical_columns = []
for feature, vocab in GENRE_FEATURES.items():
# 先转化为one-hot
cat_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=feature, vocabulary_list=vocab)
# 再转化为embedding,维度是10维
emb_col = tf.feature_column.embedding_column(cat_col, 10)
categorical_columns.append(emb_col)
tf.feature_column.categorical_column_with_identity: 指定id的最大取值,将id转化为one-hot
# movie id embedding feature
# movieId的取值应当在[0, num_buckets)
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
categorical_columns.append(movie_emb_col)
# user id embedding feature
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
categorical_columns.append(user_emb_col)
处理数值型特征#
使用tf.feature_column.numeric_column就可以了
# all numerical features
numerical_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]
定义模型#
# embedding + MLP model architecture
model = tf.keras.Sequential([
# 进行数据预处理
# 输入tf.feature_column的列表
tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
训练#
# compile the model, set loss function, optimizer and evaluation metrics
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', tf.keras.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])
# train the model
model.fit(train_dataset, epochs=5)
Epoch 1/5
7403/7403 [==============================] - 20s 3ms/step - loss: 0.4824 - accuracy: 0.7690 - auc: 0.8447 - auc_1: 0.8684
Epoch 2/5
7403/7403 [==============================] - 23s 3ms/step - loss: 0.4708 - accuracy: 0.7735 - auc: 0.8526 - auc_1: 0.8767
Epoch 3/5
7403/7403 [==============================] - 29s 4ms/step - loss: 0.4628 - accuracy: 0.7766 - auc: 0.8582 - auc_1: 0.8824
Epoch 4/5
7403/7403 [==============================] - 28s 4ms/step - loss: 0.4577 - accuracy: 0.7793 - auc: 0.8615 - auc_1: 0.8863
Epoch 5/5
7403/7403 [==============================] - 22s 3ms/step - loss: 0.4525 - accuracy: 0.7809 - auc: 0.8648 - auc_1: 0.8904
<keras.callbacks.History at 0x7fc9ab325760>
评估和预测#
# evaluate the model
test_loss, test_accuracy, test_roc_auc, test_pr_auc = model.evaluate(test_dataset)
print('Test Loss {:3f}, Test Accuracy {:3f}'.format(test_loss, test_accuracy))
print('Test ROC AUC {:3f}, Test PR AUC {:3f}'.format(test_roc_auc, test_pr_auc))
1870/1870 [==============================] - 3s 1ms/step - loss: 0.6413 - accuracy: 0.6877 - auc: 0.7420 - auc_1: 0.7672
Test Loss 0.641334, Test Accuracy 0.687656
Test ROC AUC 0.742031, Test PR AUC 0.767180
# print some predict results
predictions = model.predict(test_dataset)
# 查看9个样本的预测值和label
for prediction, label in zip(predictions[:9], list(test_dataset)[0][1][:9]):
print("prediction: {:.2f}".format(prediction[0]), "label: {}".format(label))
prediction: 0.92 label: 0
prediction: 0.01 label: 0
prediction: 0.90 label: 1
prediction: 0.15 label: 1
prediction: 0.44 label: 0
prediction: 0.53 label: 1
prediction: 0.54 label: 0
prediction: 0.28 label: 0
prediction: 0.31 label: 1