
Wide and Deep
Contents
Wide and Deep#
Note
Deep部分同Embedding+MLP,Wide部分负责记忆
结构#
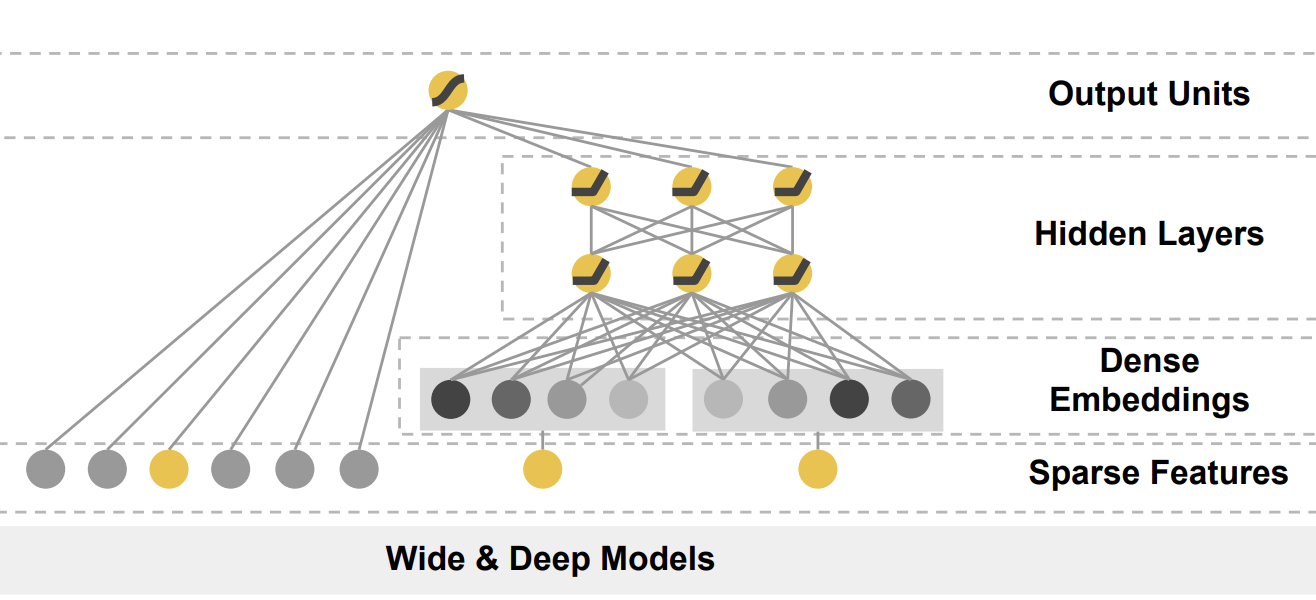
左侧是wide部分,右侧是deep部分。
wide部分:直接把输入层连接到输出层,作用是让模型有较强的记忆力。
deep部分:典型的embedding + mlp结构,作用是让模型有较强的泛化能力。
所谓“记忆能力”,即模型直接学习物品或特征的“共现频率”,并把他们直接作为推荐依据。比如说喜欢A电影的也喜欢B这个规则。
这类规则有两个特点:1.数量非常多;2.非常具体,没必要和其他特征交叉。
这样我们的Wide&Deep模型就能同时拥有记忆力和泛化能力。
数据预处理#
import tensorflow as tf
from tensorflow import keras
import rec
# 读取movielens数据集
train_dataset, test_dataset = rec.load_movielens()
df = rec.get_movielens_df()
df
| movieId | userId | rating | timestamp | label | releaseYear | movieGenre1 | movieGenre2 | movieGenre3 | movieRatingCount | ... | userRatingCount | userAvgReleaseYear | userReleaseYearStddev | userAvgRating | userRatingStddev | userGenre1 | userGenre2 | userGenre3 | userGenre4 | userGenre5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 15555 | 3.0 | 900953740 | 0 | 1995 | Adventure | Animation | Children | 10759 | ... | 92 | 1992 | 8.98 | 3.86 | 0.74 | Drama | Comedy | Thriller | Action | Crime |
| 1 | 1 | 25912 | 3.5 | 1111631768 | 1 | 1995 | Adventure | Animation | Children | 10759 | ... | 21 | 1988 | 14.09 | 3.48 | 1.28 | Action | Comedy | Romance | Adventure | Thriller |
| 2 | 1 | 29912 | 3.0 | 866820360 | 0 | 1995 | Adventure | Animation | Children | 10759 | ... | 4 | 1995 | 0.50 | 3.00 | 0.00 | NaN | NaN | NaN | NaN | NaN |
| 3 | 10 | 17686 | 0.5 | 1195555011 | 0 | 1995 | Action | Adventure | Thriller | 6330 | ... | 35 | 1992 | 8.35 | 2.97 | 1.48 | Comedy | Drama | Adventure | Action | Thriller |
| 4 | 104 | 20158 | 4.0 | 1155357691 | 1 | 1996 | Comedy | NaN | NaN | 3954 | ... | 81 | 1991 | 8.70 | 3.60 | 0.72 | Thriller | Drama | Action | Crime | Adventure |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 88822 | 968 | 26865 | 3.0 | 854092232 | 0 | 1968 | Horror | Sci-Fi | Thriller | 1824 | ... | 94 | 1991 | 12.23 | 3.35 | 0.85 | Drama | Thriller | Comedy | Crime | Romance |
| 88823 | 968 | 8507 | 2.0 | 974709061 | 0 | 1968 | Horror | Sci-Fi | Thriller | 1824 | ... | 5 | 1994 | 0.89 | 2.00 | 1.00 | NaN | NaN | NaN | NaN | NaN |
| 88824 | 969 | 16689 | 5.0 | 857854044 | 1 | 1951 | Adventure | Comedy | Romance | 2380 | ... | 97 | 1992 | 9.95 | 3.53 | 0.82 | Drama | Comedy | Crime | Romance | Thriller |
| 88825 | 969 | 26460 | 2.0 | 1250279576 | 0 | 1951 | Adventure | Comedy | Romance | 2380 | ... | 55 | 1990 | 11.78 | 2.73 | 1.42 | Thriller | Crime | Drama | Comedy | Sci-Fi |
| 88826 | 970 | 3033 | 2.0 | 1272394603 | 0 | 1953 | Adventure | Comedy | Crime | 98 | ... | 100 | 1985 | 17.64 | 3.67 | 0.89 | Drama | Romance | Comedy | Thriller | Crime |
88827 rows × 27 columns
Deep部分#
就像上一节那样处理
# 电影的类别
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War',
'Comedy', 'Western', 'Documentary', 'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
# 类别列
GENRE_FEATURES = {
'userGenre1': genre_vocab,
'userGenre2': genre_vocab,
'userGenre3': genre_vocab,
'userGenre4': genre_vocab,
'userGenre5': genre_vocab,
'movieGenre1': genre_vocab,
'movieGenre2': genre_vocab,
'movieGenre3': genre_vocab
}
categorical_columns = []
for feature, vocab in GENRE_FEATURES.items():
# 先转化为one-hot
cat_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=feature, vocabulary_list=vocab)
# 再转化为embedding,维度是10维
emb_col = tf.feature_column.embedding_column(cat_col, 10)
categorical_columns.append(emb_col)
# movie id embedding feature
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
categorical_columns.append(movie_emb_col)
# user id embedding feature
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
categorical_columns.append(user_emb_col)
# all numerical features
numerical_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]
Wide部分#
使用两个特征的交叉
# define input for keras model
inputs = {
'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),
'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),
'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),
'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),
'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),
'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),
'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),
'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),
'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),
'userRatedMovie1': tf.keras.layers.Input(name='userRatedMovie1', shape=(), dtype='int32'),
'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),
'userGenre2': tf.keras.layers.Input(name='userGenre2', shape=(), dtype='string'),
'userGenre3': tf.keras.layers.Input(name='userGenre3', shape=(), dtype='string'),
'userGenre4': tf.keras.layers.Input(name='userGenre4', shape=(), dtype='string'),
'userGenre5': tf.keras.layers.Input(name='userGenre5', shape=(), dtype='string'),
'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),
'movieGenre2': tf.keras.layers.Input(name='movieGenre2', shape=(), dtype='string'),
'movieGenre3': tf.keras.layers.Input(name='movieGenre3', shape=(), dtype='string'),
}
rated_movie = tf.feature_column.categorical_column_with_identity(key='userRatedMovie1',
num_buckets=1001)
# 使用movie_col和rated_movie的交叉作为wide部分的输入
crossed_feature = tf.feature_column.indicator_column(
tf.feature_column.crossed_column([movie_col, rated_movie], 10000))
定义模型#
使用keras的函数式API进行定义。
# wide and deep model architecture
# deep part for all input features
deep = tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns)(inputs)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
# wide part for cross feature
wide = tf.keras.layers.DenseFeatures(crossed_feature)(inputs)
both = tf.keras.layers.concatenate([deep, wide])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(both)
model = tf.keras.Model(inputs, output_layer)
训练#
# compile the model, set loss function, optimizer and evaluation metrics
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', tf.keras.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])
# train the model
model.fit(train_dataset, epochs=5)
Epoch 1/5
/Users/facer/opt/anaconda3/lib/python3.8/site-packages/keras/engine/functional.py:582: UserWarning: Input dict contained keys ['rating', 'timestamp', 'userRatedMovie2', 'userRatedMovie3', 'userRatedMovie4', 'userRatedMovie5', 'userAvgReleaseYear', 'userReleaseYearStddev'] which did not match any model input. They will be ignored by the model.
warnings.warn(
7403/7403 [==============================] - 24s 3ms/step - loss: 0.7510 - accuracy: 0.6077 - auc: 0.6272 - auc_1: 0.6638
Epoch 2/5
7403/7403 [==============================] - 20s 3ms/step - loss: 0.6049 - accuracy: 0.6767 - auc: 0.7304 - auc_1: 0.7556
Epoch 3/5
7403/7403 [==============================] - 21s 3ms/step - loss: 0.5482 - accuracy: 0.7214 - auc: 0.7897 - auc_1: 0.8113
Epoch 4/5
7403/7403 [==============================] - 20s 3ms/step - loss: 0.5051 - accuracy: 0.7546 - auc: 0.8270 - auc_1: 0.8471
Epoch 5/5
7403/7403 [==============================] - 20s 3ms/step - loss: 0.4816 - accuracy: 0.7691 - auc: 0.8452 - auc_1: 0.8668
<keras.callbacks.History at 0x7fb47ea620a0>