
NeuralCF
Contents
NeuralCF#
Note
将矩阵分解中的內积操作改为神经网络,我们就得到了NeuralCF模型。
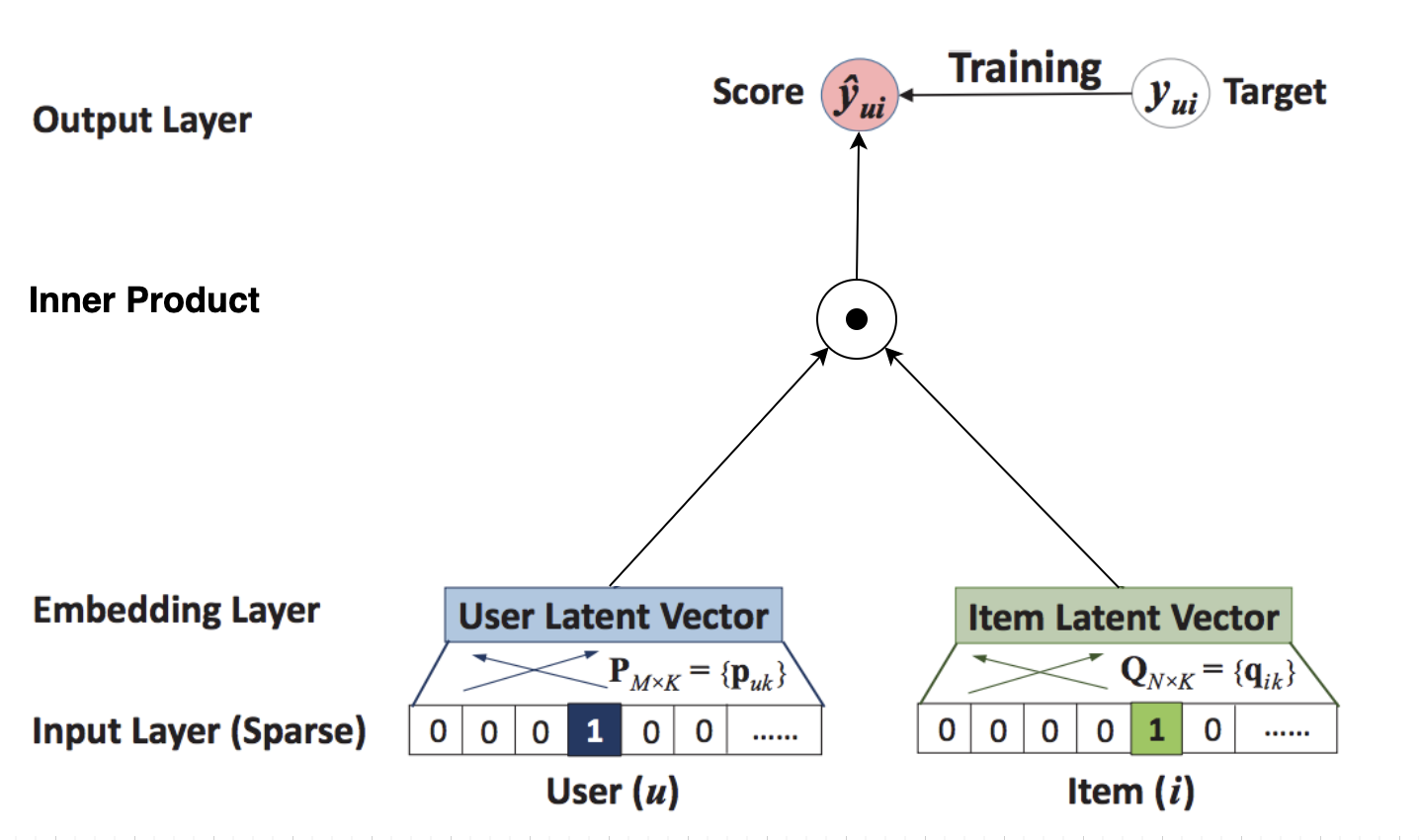
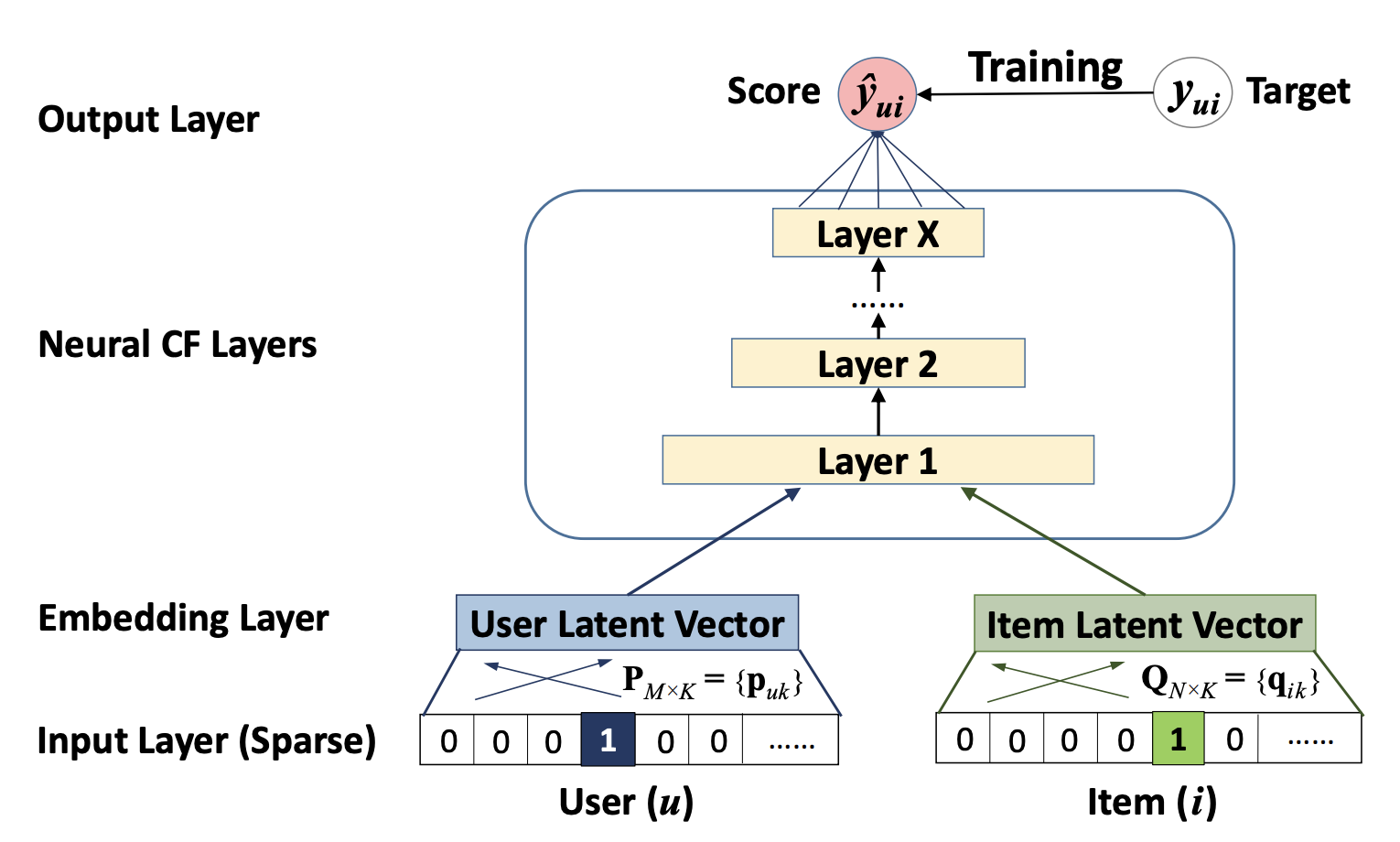
双塔模型#
NeuralCF的模型结构中,蕴含了一个非常有价值的思想,就是我们可以把模型分为用户侧模型和物品侧模型两个部分,然后用互操作层把这两部分联合起来,产生最后的得分。
这里用户侧和物品侧模型结构,可以是简单的Embedding层,也可以是复杂的神经网络。
互操作层可以是简单的点积操作,也可以是比较复杂的MLP结构。
这种用户侧模型 + 物品侧模型 + 互操作层的结构,统称为“双塔模型结构”。
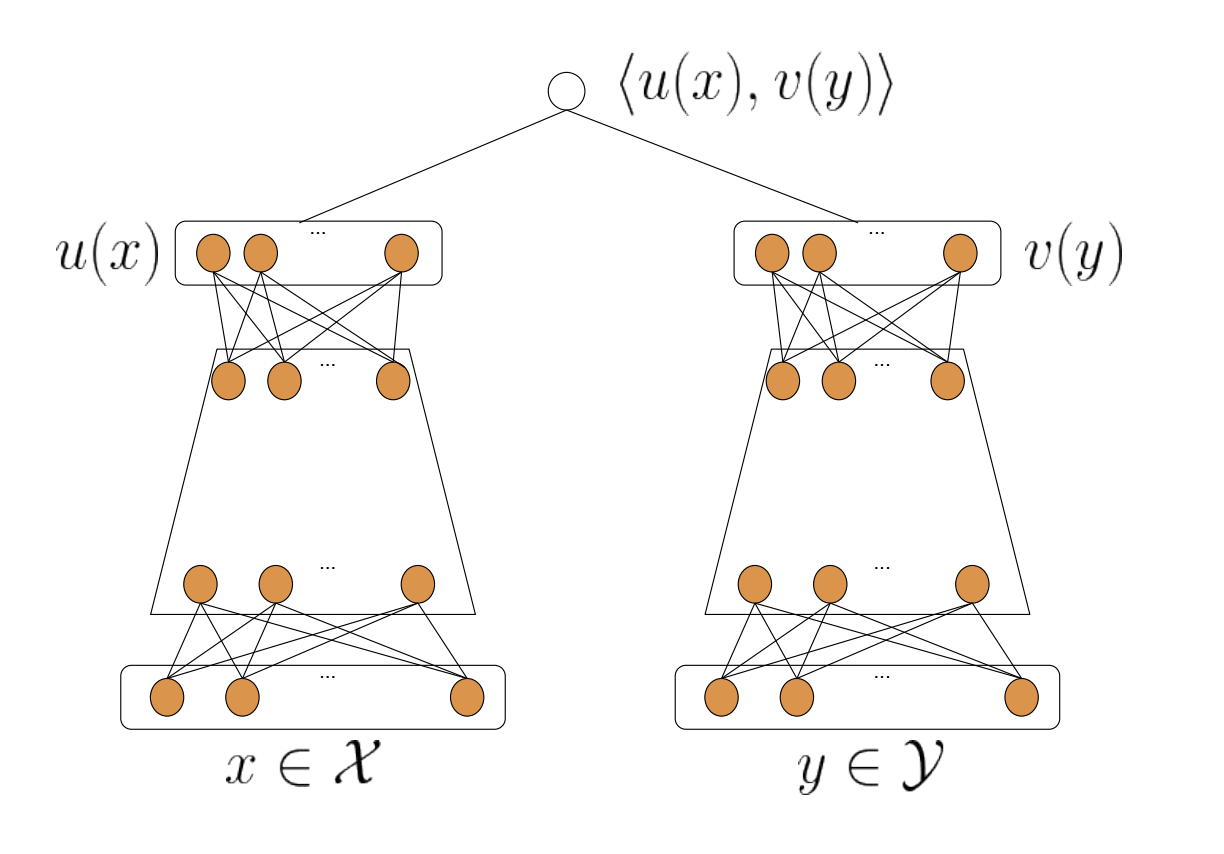
上面是一个复杂用户侧和物品侧模型 + 简单互操作层的双塔模型。
双塔模型具有易上线,易服务的优势。
使用双塔模型,我们可以不用把整个模型部署上线,只需预存用户塔和物品塔的输出(比如说预存到redis),即用户Embedding和物品Embedding,线上只用实现互操作层,又快又简单。
数据预处理#
我们只使用movieId和userId列
import tensorflow as tf
from tensorflow import keras
import rec
# 读取movielens数据集
train_dataset, test_dataset = rec.load_movielens()
# movie id embedding feature
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
# user id embedding feature
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
inputs = {
'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),
'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),
}
模型#
def neural_cf_model(feature_inputs, item_feature_columns, user_feature_columns, hidden_units):
"""实现neuralcf模型"""
item_tower = tf.keras.layers.DenseFeatures(item_feature_columns)(feature_inputs)
user_tower = tf.keras.layers.DenseFeatures(user_feature_columns)(feature_inputs)
interact_layer = tf.keras.layers.concatenate([item_tower, user_tower])
# hidden_units指定了MLP的结构
for num_nodes in hidden_units:
interact_layer = tf.keras.layers.Dense(num_nodes, activation='relu')(interact_layer)
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(interact_layer)
neural_cf_model = tf.keras.Model(feature_inputs, output_layer)
return neural_cf_model
# NeuralCF模型
model = neural_cf_model(inputs, [movie_emb_col], [user_emb_col], [10, 10])
训练#
# compile the model, set loss function, optimizer and evaluation metrics
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', tf.keras.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])
# train the model
model.fit(train_dataset, epochs=5)
Epoch 1/5
/Users/facer/opt/anaconda3/lib/python3.8/site-packages/keras/engine/functional.py:582: UserWarning: Input dict contained keys ['rating', 'timestamp', 'releaseYear', 'movieGenre1', 'movieGenre2', 'movieGenre3', 'movieRatingCount', 'movieAvgRating', 'movieRatingStddev', 'userRatedMovie1', 'userRatedMovie2', 'userRatedMovie3', 'userRatedMovie4', 'userRatedMovie5', 'userRatingCount', 'userAvgReleaseYear', 'userReleaseYearStddev', 'userAvgRating', 'userRatingStddev', 'userGenre1', 'userGenre2', 'userGenre3', 'userGenre4', 'userGenre5'] which did not match any model input. They will be ignored by the model.
warnings.warn(
7403/7403 [==============================] - 16s 2ms/step - loss: 0.6230 - accuracy: 0.6457 - auc: 0.6978 - auc_1: 0.7412
Epoch 2/5
7403/7403 [==============================] - 15s 2ms/step - loss: 0.5661 - accuracy: 0.7076 - auc: 0.7706 - auc_1: 0.7985
Epoch 3/5
7403/7403 [==============================] - 15s 2ms/step - loss: 0.5144 - accuracy: 0.7471 - auc: 0.8189 - auc_1: 0.8445
Epoch 4/5
7403/7403 [==============================] - 14s 2ms/step - loss: 0.4705 - accuracy: 0.7757 - auc: 0.8531 - auc_1: 0.8775
Epoch 5/5
7403/7403 [==============================] - 14s 2ms/step - loss: 0.4318 - accuracy: 0.7988 - auc: 0.8788 - auc_1: 0.9015
<keras.callbacks.History at 0x7f91c3b895b0>