基础架构
Contents
基础架构#
推荐系统的逻辑架构#
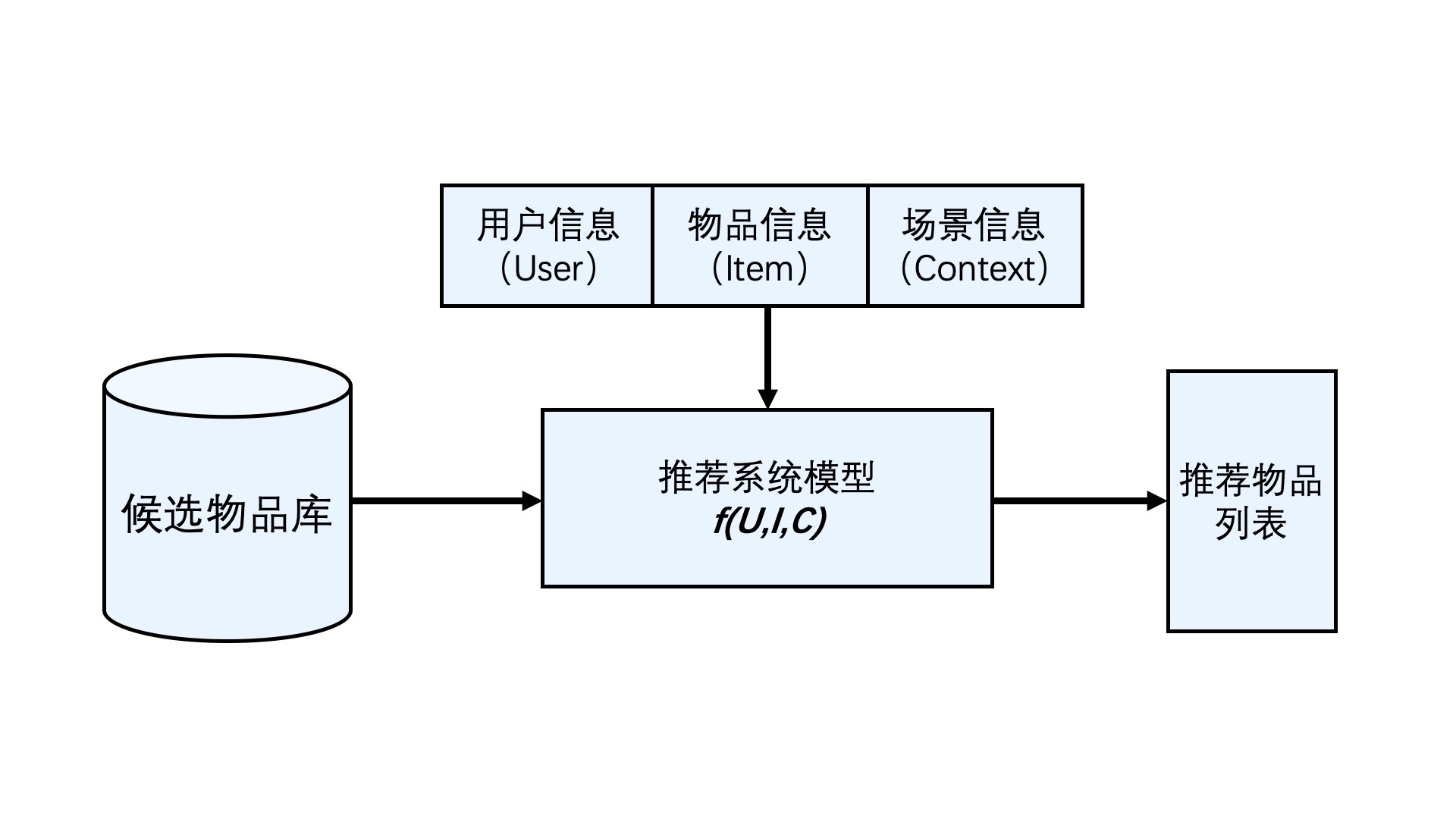
推荐系统要解决的问题用一句话总结就是:用户如何高效获取感兴趣的信息的问题。
可形式化定义为:
对于某个用户U(User),在特定场景C(Contex)下,针对海量的“物品”信息构建一个函数,预测用户对特定候选物品(item)的喜好程度,再根据喜好程度对所有候选物品排序,生成推荐列表的问题。
由此可以抽象出推荐系统的逻辑架构:
推荐系统的技术架构#
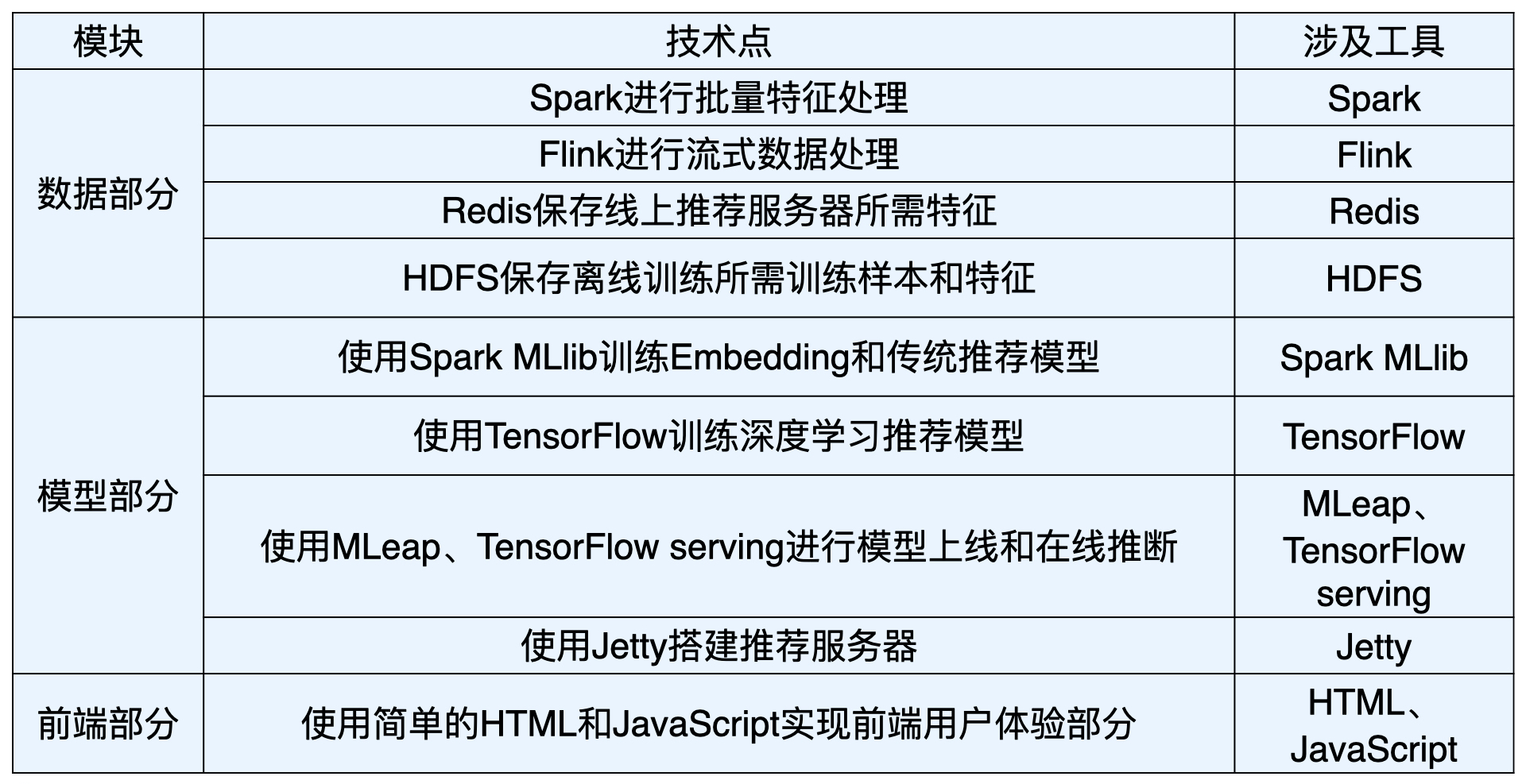
在实际的推荐系统中,工程师需要着重解决的问题有两类。
一类与数据和信息相关,即“用户信息”“物品信息”“场景信息”分别是什么,如何存储、更新和处理数据?
另一类与推荐系统算法和模型相关,即推荐系统模型如何训练、预测,以及如何达成更好的推荐效果?
一个工业级的推荐系统的技术架构也是按照这两部分展开的
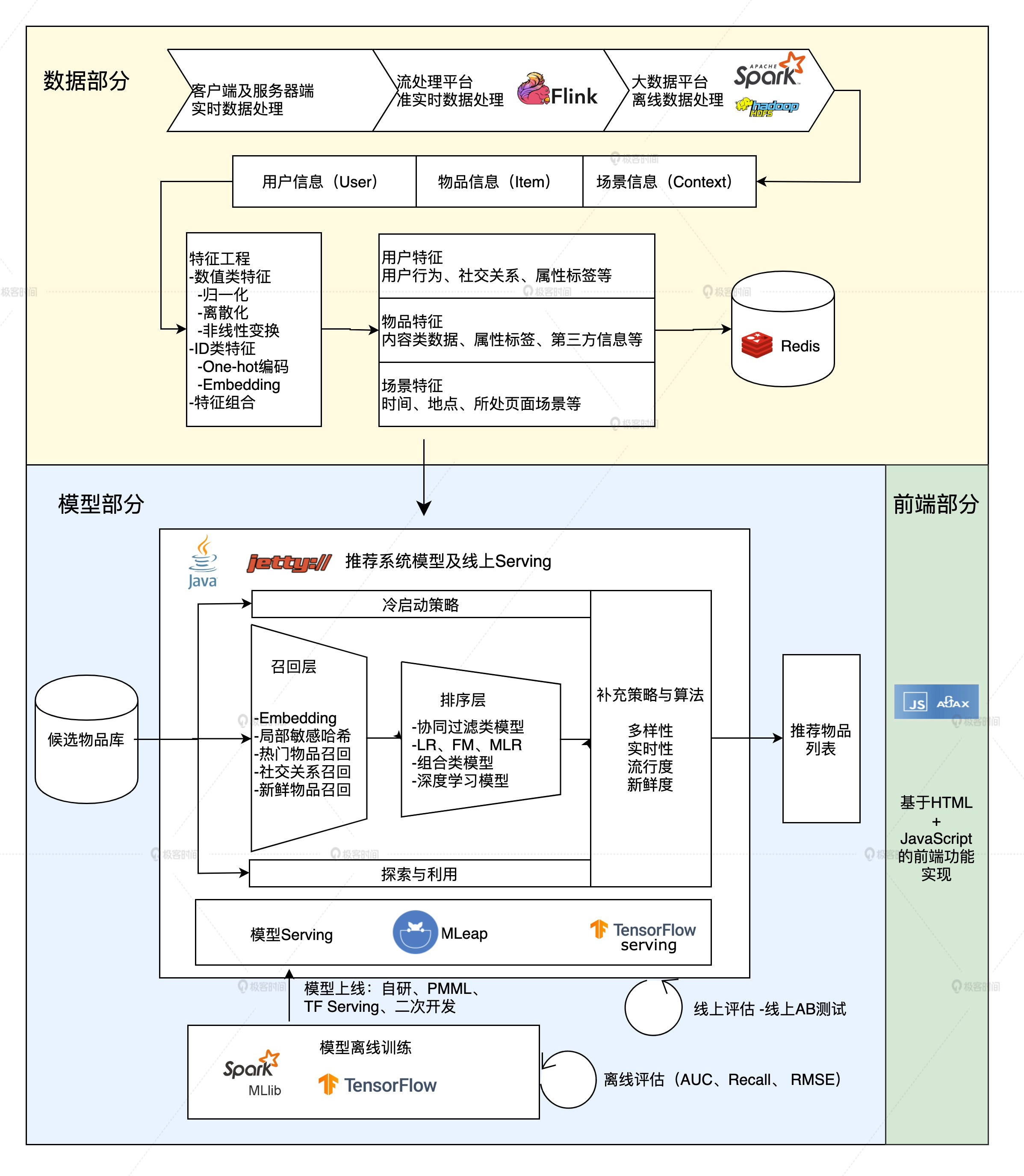
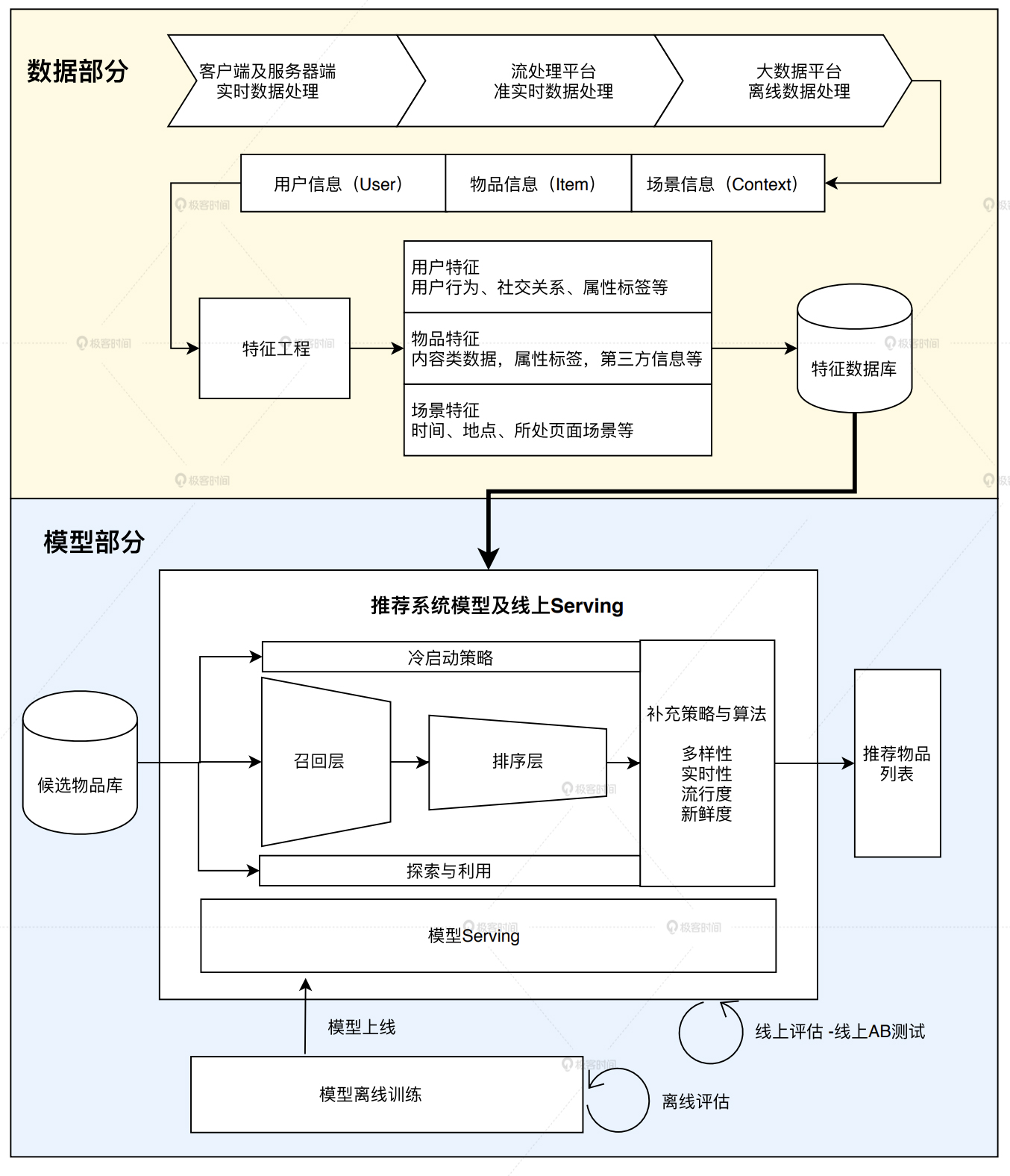
“数据和信息”部分逐渐发展为融合数据离线批处理、实时流处理的数据流框架。
“算法和模型”部分则进一步细化为推荐系统中,集训练(training)、评估(evaluation)、部署(deployment)、线上推断(online inference)为一体的模型框架。
由此可总结出一个典型推荐系统的技术架构图:
推荐系统的数据部分#
推荐系统的“数据部分”负责“用户”“物品”“场景”信息的收集和处理。
根据处理数据量和实时性不同,可分为客户端和服务端实时数据处理、流平台(Flink等)准实时数据处理、大数据平台(Spark等)离线数据处理。
数据平台根据对日志,物品和用户元数据等信息的处理,获得推荐模型的训练数据、特征数据、统计数据。
数据平台加工后的数据出口主要有3个:
生成推荐系统模型所需的样本数据,用于模型的训练和评估。
生成推荐系统模型服务(Model Serving)所需的特征,用于线上推断。
生成系统监控等所需的统计型数据。
推荐系统的模型部分#
“模型部分”是推荐系统的主体,模型的结构主要由“召回层”、“排序层”以及“补充策略和算法层”组成。
召回层:由高效的召回规则、算法或简单的模型组成,让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。
排序层:利用排序模型对初筛的候选集进行精排序。
补充策略和算法层:为兼顾结果的多样性、流行度、新鲜度等指标,对推荐列表进行一定的调整。
他们都是通过模型线上Serving来实现的(如Tensorflow serving)。
而模型要serving,首先需要训练好模型,才能将其部署到线上。
模型训练可分为离线训练和在线更新两部分。离线训练利用全量样本和特征,使模型逼近全局最优解;在线更新可以更实时的消化新数据,满足模型实时性的要求。
最后,为了评估推荐系统模型的效果,以及模型的快速迭代优化,推荐系统还需要“离线评估”“线上A/B测试”等评估模块,用来得到线下和线上评估指标,指导下一步的模型迭代优化。