
流动的 Word Count¶
Note
今天的大数据处理,对于延迟性的要求越来越高,因此流处理的基本概念与工作原理,是每一个大数据从业者必备的“技能点”。
我们从一个”流动的 Word Count“入手,去学习一下在流计算的框架下,Word Count 是怎么做的。
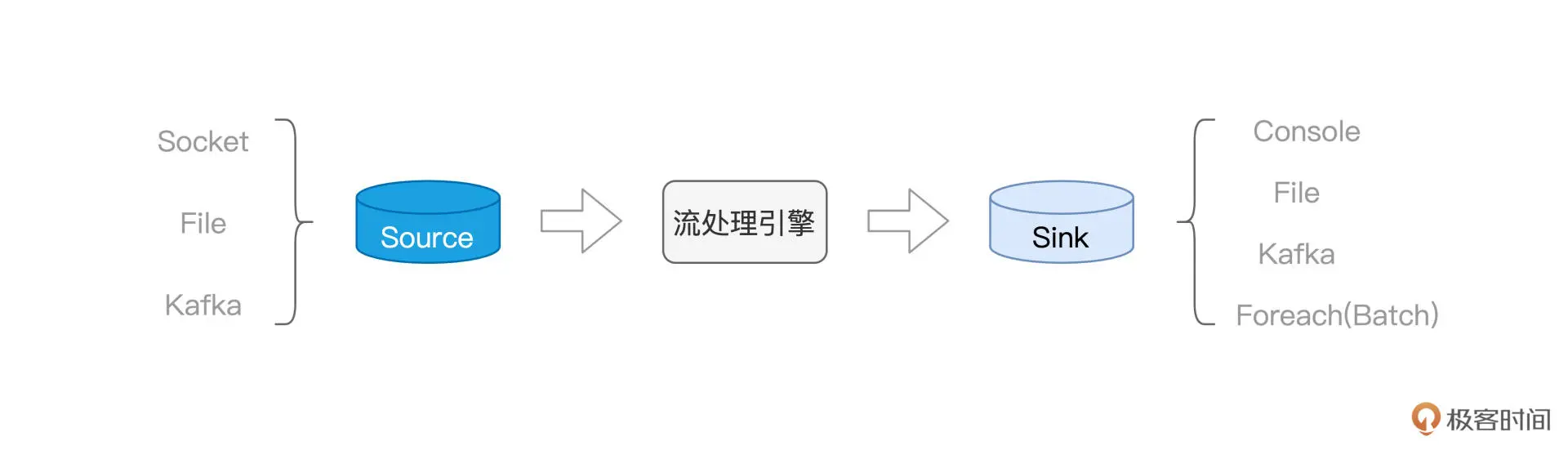
Source¶
在“流动的 Word Count”里,数据以行为粒度,分批地“喂给”Spark,每一行数据,都会触发一次 Job 计算。
具体来说,我们使用 netcat 工具,向本地 9999 端口的 Socket 地址发送数据行:
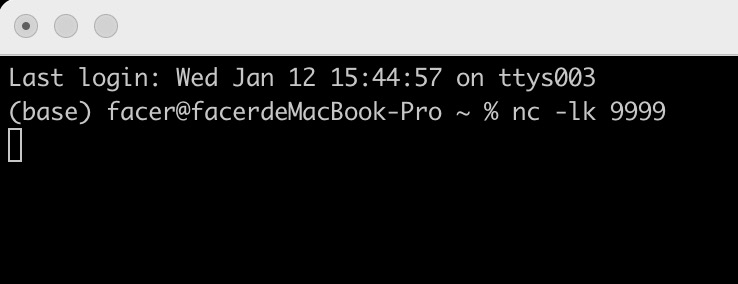
而 Spark 流处理应用,则时刻监听着本机的 9999 端口,一旦接收到数据条目,就会立即触发计算逻辑的执行。
流处理引擎¶
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("stream word count").getOrCreate()
# 从监听地址创建 DataFrame
df = (spark.readStream
.format("socket")
.option("host", "127.0.0.1")
.option("port", 9999)
.load())
import pyspark.sql.functions as F
# 先把字符串以空格为分隔符做拆分,得到单词数组 words
# 再把数组 words 展平为单词 word
df = (df
.withColumn("words", F.split("value", " "))
.withColumn("word", F.explode("words"))
.groupBy("word").count())
Sink¶
在 Complete mode 下,每一批次的计算结果,都会包含系统到目前为止处理的全部数据内容。
在 Update mode 下,每个批次仅输出内容有变化的数据记录。
# 指定Sink为终端
# 指定输出选项
# 指定输出模式
# 启动流处理应用
# 等待中断指令
(df.writeStream.format("console")
.option("truncate", False)
.outputMode("complete")
.start()
.awaitTermination())