
Spark 配置项¶
Note
要让 Spark 代码跑得又快又稳,我们需要配置项来帮忙。
我们主要关注内存、CPU和磁盘相关的配置项。
可以使用命令行参数或 SparkConf 对象进行配置。
内存¶
Spark 的内存划分如下图所示:
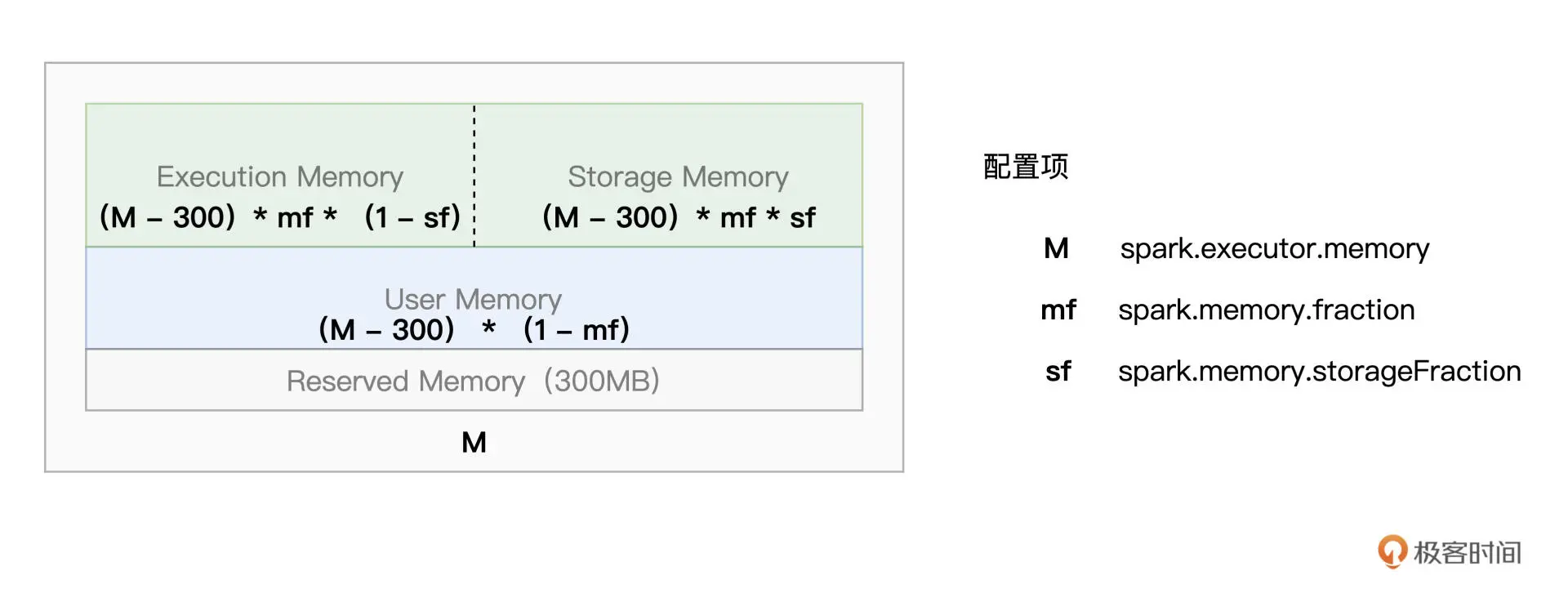
from pyspark import SparkConf
conf = SparkConf().setAppName("config").setMaster("local")
# Executor 可用内存总大小
conf.set("spark.executor.memory", "4g")
# 除 User Memory 以外的内存空间占比
conf.set("spark.memory.fraction", 0.8)
# Storage Memory 内存空间占比
conf.set("spark.memory.storageFraction", 0.5)
<pyspark.conf.SparkConf at 0x7fbd0f24d850>
CPU¶
# 集群范围内 Executors 总数
conf.set("spark.executor.instances", 1)
# 每个 Executor 可用的 CPU Cores
conf.set("spark.executor.cores", 4)
# 默认的 RDD(由 parallelize 创建)并行度
conf.set("spark.default.parallelism", 4)
# Shuffle Read(Reduce)阶段默认并行度
conf.set("spark.sql.shuffle.partitions", 4)
<pyspark.conf.SparkConf at 0x7fbd0f24d850>
磁盘¶
# 用于存储 Shuffle 中间文件和 RDD Cache 的本地文件系统目录
conf.set("spark.local.dir", "/tmp")
<pyspark.conf.SparkConf at 0x7fbd0f24d850>
命令行参数¶
除使用 SparkConf 对象进行配置外,还可以使用命令行参数,它的优先级相对低
spark-submit --master local[*] --conf spark.executor.cores=2 --conf spark.executor.memory=4g --conf spark.local.dir=/ssd_fs/large_dir