
BERT¶
Note
BERT的全程为Bidirectional Encoder Representations from Transformers,是一个预训练的语言表征模型。
BERT的优点有:
可以表示整个文本序列而不仅仅是一个单词
它使用双向的Transformer进行预训练,可以生成深层的双向语言表征
在BERT预训练后,只需添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中获得很好的表现。
ELMo¶
之前我们介绍的word2vec和GloVe都将相同的预训练向量分配给同一个词,而不考虑上下文。然而自然语言中有着丰富的多义现象,上下文无关表示具有明显的局限性。
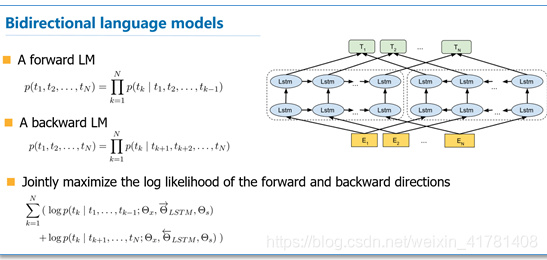
这种需求推动了“上下文敏感”词表示的发展,比如ELMo(Embeddings from Language Models)将整个序列作为输入,使用预训练的双向LSTM模型为输入序列的的每个单词分配一个表示。ELMo的目标函数是前向和反向语言模型的最大似然,预训练是自监督的。
应用时ELMo的表示将作为附加特征添加到下游任务的现有监督模型中,如将ELMo的表示和GloVe的表示连结起来。
GPT¶
ELMo的每个解决方案仍然依赖于一个特定于任务的结构。
GPT(Generative Pre Training)模型为上下文的敏感表示设计了通用的任务无关模型。GPT建立在Transformer解码器的基础之上,预训练了一个用于表示文本序列的语言模型。当GPT应用于下层任务时,语言模型的输出将被送到一个附加的线性输出层,用于预测任务的标签。
和ELMo冻结预训练模型参数不同,GPT在下游任务的监督学习过程中对预训练Transformer解码器的所有参数进行微调。

输入表示¶
在自然语言处理中,有些任务(如情感分析)为单个文本作为输入,有些任务(如自然语言推理)以一对文本作为输入。
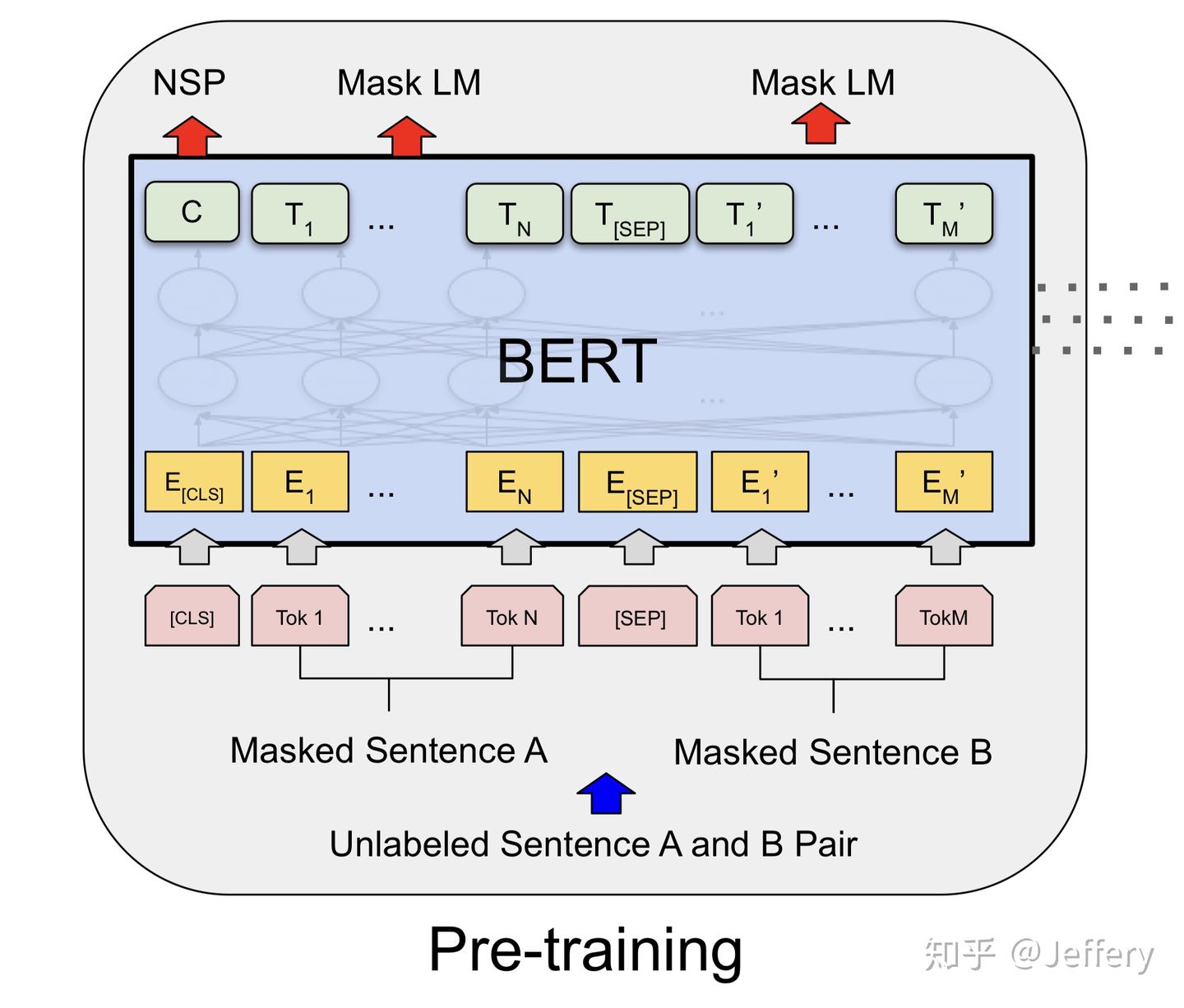
当输入为单个文本时,BERT输入序列是开始词元<cls>、文本序列、一级分隔词元<sep>的连结。
当输入为文本对时,BERT输入序列是<cls>、第一段文本序列、<sep>、第二段文本序列、<sep>的连结。

BERT选择Transformer的编码器作为其双向结构,它在原有Token Embeddings和Positional Embeddings的基础上加上了可学习的Segment Embedding,它用于区分第一和第二段文本,当输入为单文本时,仅使用 \(\mathbf{e}_{A}\)。
预训练任务¶
预训练包括两个任务:遮蔽语言模型(Masked Language Modeling)和下一句预测(Next Sentence Prediction)。
遮蔽语言模型¶
BERT随机遮蔽词元并使用来自双向上下文的信息以自监督的方式预测遮蔽词元。
在这个预训练任务中,将随机选择15%的词元作为预测的遮蔽词元。一个直接的方法是用一个特殊的<mask>替换要预测的词元,然而人造特殊词元<mask>不会出现在微调中,因此为了避免预训练和微调间的不匹配,将输入替换为:
80%为特殊的
<mask>词元10%不变
10%为随机词元
遮蔽语言模型添加一个浅层的MLP来进行预测,输入为BERT的相应编码结果,如下图所示:
下一句预测¶
尽管遮蔽语言模型能够编码双向上下文来表示单词,但它不能显示地建模文本对之间的逻辑关系。
BERT因此在预训练中考虑了一个二分类任务-下一句预测,在为预训练生成句子对时,有一半是标签为“真”的连续句子,另一半是标签为“假”的随机句子对。
下一句预测添加一个浅层MLP来进行预测,我们注意到词元<cls>的表示可以对输入的两个句子进行编码,因此MLP的输入时<cls>的表示。