
Word2vec¶
Note
Word2vec是一种训练词向量的技术,它将词映射到一个固定长度的向量,这些向量能很好地表达不同词之间的相似性和类比关系。
Word2vec有Skip-Gram和CBOW两种构型。
Skip-Gram¶
Skip-Gram假设一个词可以用来在文本序列中生成其周围的单词。

这个想法可以通过训练一个预测周围单词的两层神经网络来实现。
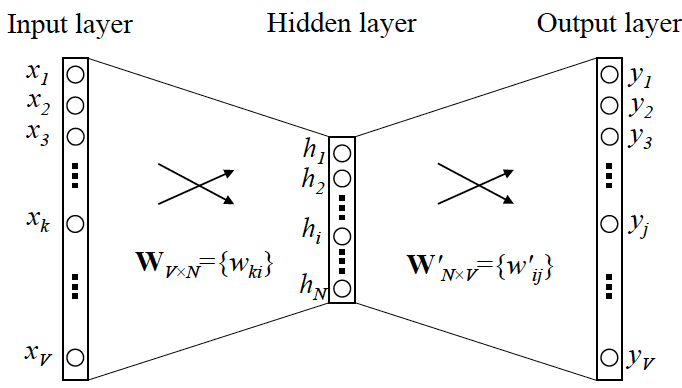
此神经网络输入和输出的维度为 \(V\),即我们要训练的词汇量,隐藏层的维度 \(N\) 为词向量的维度。
假设中心词的索引为 \(k\),其周围单词的索引为 \(1j, ..., Cj\)。
那么输入可以表示为一个one-hot向量:\(x_{k}=1\)其他维度为0。按照我们的设想此时的输出 \(y_{j}\) 表示单词 \(k\) 周围出现单词 \(j\) 的可能性,因此我们期望 \(y_{1j}, ..., y_{Cj}\) 尽可能相对大。
训练完成后,我们将各个单词对应的隐藏层输出作为此单词的词向量,它是 \(N\) 维的,包含了其周围单词分布的信息。
训练¶
上面我们讲了Skip-Gram模型的基本思路,但是具体的训练目标是什么呢?
首先我们使用softmax操作将输出解释为条件概率:
可以将训练目标定为最小化负对数似然函数:
负采样¶
若使用上面的目标函数进行训练,由于softmax存在归一化项,每步迭代都需要对所有单词进行遍历,训练速度很慢。
因此一般我们会使用负采样来进行加速近似训练。负采样从预定义分布中采样负样本或者说噪声词,一个周边单词对应数个非此窗口的噪声词。
假设采样到的噪声词的索引为 \(1n, ..., Mn\),那么此次迭代仅需要让 \(\sigma(y_{1j}),...,\sigma(y_{Cj})\) 尽可能大,且 \(\sigma(y_{1n}),...,\sigma(y_{Mn})\) 尽可能小即可,不需要遍历所有的单词。
根据word2vec论文的建议,噪声词\(w\)的采样概率\(P(w)\)与其在字典中出现频次的0.75次方成正比。
下采样¶
文本数据中通常有“the”、“a”等高频词,这些词在上下文窗口中与许多不同的词共同出现,提供的有用信息很少。
因此,当训练词嵌入模型时,可以对高频单词进行下采样。具体地说,每个单词\(w_{i}\)留下的概率为:
其中 \(f(w_{i})\) 是 \(w_{i}\) 的词数与数据集总词数的比率,常量 \(t\) 是超参数(比如说\(10^{-4}\))。只有当 \(f(w_{i}) > t\) 时,词 \(w_{i}\) 才有可能被抛弃,比率越高抛弃概率越大。
