
Automatic Differentiation#
Note
求导是几乎所有深度学习优化算法的关键步骤,我们可以使用PyTorch自动求导。
一个简单的例子#
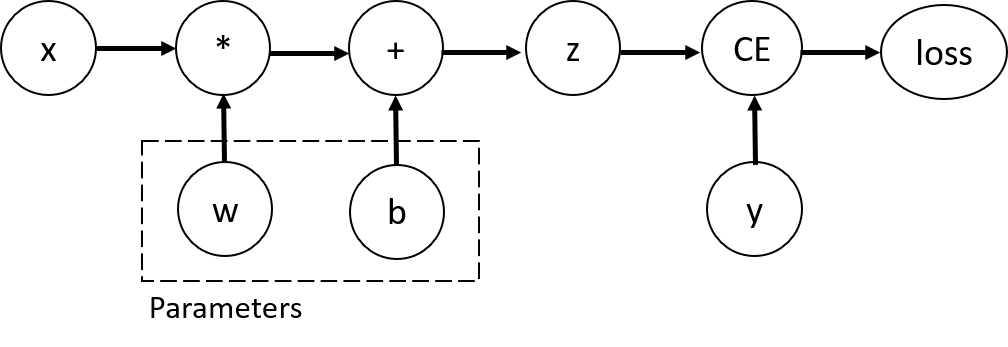
考虑最简单的单层神经网络,输入是x,参数是w和b,并定义好损失函数:
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w) + b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
autograd记录上述数据和操作流,构成一个有向无环图(DAG):
print('Gradient function for z =', z.grad_fn)
print('Gradient function for loss =', loss.grad_fn)
Gradient function for z = <AddBackward0 object at 0x7fd51b73db80>
Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward0 object at 0x7fd51b6f04c0>
反向传播会给出requires_grad=True的叶子节点的梯度
loss.backward()
print(w.grad)
print(b.grad)
tensor([[0.2274, 0.0553, 0.0321],
[0.2274, 0.0553, 0.0321],
[0.2274, 0.0553, 0.0321],
[0.2274, 0.0553, 0.0321],
[0.2274, 0.0553, 0.0321]])
tensor([0.2274, 0.0553, 0.0321])
需要注意的点#
Warning
一个计算图只能反向传播一次,除非在反向传播时设置retain_graph=True
比如说,现在执行以下操作会抛出异常
loss.backward()
Warning
Pytorch会自动累计grad,除非手动清零
inp = torch.eye(3, requires_grad=True)
out = (inp + 1).pow(2)
# 要进行多次backward需设置retain_graph=True
out.backward(torch.ones_like(inp), retain_graph=True)
print(inp.grad)
# 累计grad
out.backward(torch.ones_like(inp), retain_graph=True)
print(inp.grad)
# 清零grad
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print(inp.grad)
tensor([[4., 2., 2.],
[2., 4., 2.],
[2., 2., 4.]])
tensor([[8., 4., 4.],
[4., 8., 4.],
[4., 4., 8.]])
tensor([[4., 2., 2.],
[2., 4., 2.],
[2., 2., 4.]])
Note
Pytorch使用动态DAG,即在每次.backward()后,都会重新生成DAG,这使得我们可以在模型中使用Python控制流。
def func(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
return b
a = torch.randn(size=(), requires_grad=True)
c = func(a)
c.backward()
a.grad
tensor(1024.)
禁用梯度跟踪#
有时,我们希望将某些计算移动到计算图之外,比如说:
finetune时
预测时
z = torch.matmul(x, w) + b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w) + b
print(z.requires_grad)
True
False
使用.detach()也可以达到同样的效果。
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
False